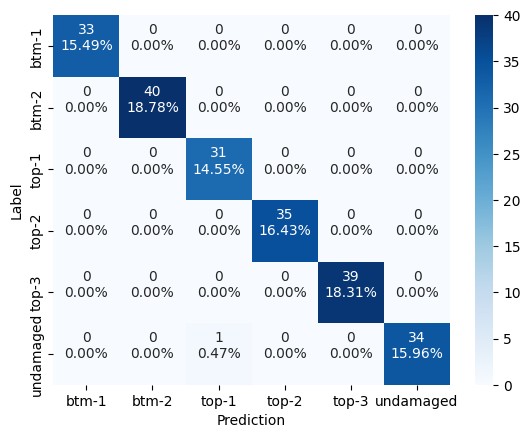
Here is my confusion matrix after fixing question 2:
I will let you make it yourself ![]()
Here is my confusion matrix after fixing question 2:
I will let you make it yourself ![]()
Looks rather better!
I’m trying to find out how to match y_true, but I’m really not yet familiar with tensorflow and Keras. I tried to make a copy of the whole dataset to predict (therefore the labels don’t change) but it still failed.
Would you give me some hints or documents that I can look into? I’m feeling rather stuck right now.
Also how did you achieve such a high accuracy? I didn’t achieve this accuracy before! How did you train the network?
Thank you for helping!
Yuhan
To train the network, you have to be sure that the examples and the labels are in exactly the same order.
Yours were scrambled (the labels did not line up with the examples), so you were essentially getting totally random results.
Hi Yuhan @Chiang_Yuhan,
This post is for your first question.
Firstly,
so, to get rid of two orderings, you can get both y_true and y_pred at the first run of train_dataset. To get both, you need to rethink about how to do model.predict.
Secondly, your confusion matrix is against the training set, which we usually don’t do. It’s more often against the validation set (or a test set, if any). On the other hand, while we shuffle the training set for some reasons, shuffling the validation set (and the test set) gives us NO advantage at all. Therefore, if your matrix had been against a validation set WITHOUT shuffled, the whole thing would have been much easier. Can you see that?
So, think about what you want to do next.
Maybe also think/research about why do we want to shuffle only the training set.
For the second one,
Remember you gave me a smaller dataset, and remember your matrix is against the training set?
Because I have not changed anything about your training code, I suppose now the network architecture is too big for the reduced training set and thus is overfitting. Make sense?
You would have seen 100% accuracy if you had run your code with the dataset you shared. Let’s do our best to be on the same page ![]()
![]()
Hello @rmwkwok ,
Thank you for your insight! I think I would not shuffle the validation set and use it for the confusion matrix. Yet I still have a question that is bothering me.
In my program, I use this network to train the test set and validation set at the same time with the line
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=epochs
)
I used this line in what I learned in DLS course. If I don’t shuffle the validation set, is there a possibility that the model learns the ‘pattern of the sequence of the data’ instead of the features of the data? Instead of learning the features that would identify a class A, it learns the sequence of data is class A, A, A, A, B, B, B. Thus the network will not learn well. Should I not train the network with validation set?
Thank you for reading this message.
Best,
Yuhan
Thank you for the reply!
I think it is not scrambled when I train the network, but somehow I messed it up when I was plotting the confusion matrix. The network has 80% accuracy but the confusion matrix does not reflex that (it seems quite random).
Best,
Yuhan
Hi @Chiang_Yuhan,
Although we do give model.fit both train_dataset and validation_dataset as input arguments, tensorflow ONLY uses train_dataset to do gradient descent and update the network’s weights.
Tensorflow, on the other hand, measures the network’s metric and loss values using the validation dataset at the end of each epoch.
So, what do you think now?
This makes a lot more sense now! Yet I still have a small question:
By reading your insight on
“shuffling the validation set (and the test set) gives us NO advantage at all. Therefore, if your matrix had been against a validation set WITHOUT shuffled, the whole thing would have been much easier. Can you see that?”
I have decided to turn off the shuffle in the validation set and use the validation set to plot the confusion matrix. When I print the labels, I have found out that I don’t have a good mix of all the classes. The upper list is the labels of the training set and the lower list is the labels of validation set.
I’m curious if I’m on the right track and how did your resolve this issue?
Here is the code of how I printed the labels, is it valid? I got it from a thread on stackoverload.
Best,
Yuhan
Think for 5 minutes and then tell me if you can give me a reason why ordered validation set is an issue?
Sure! Let me give it a try!
Yes, it is correct.
Well since the ordered validation set does not effect the weight and biases it doesn’t post an issue on further learning according to your insight:
“Tensorflow, on the other hand, measures the network’s metric and loss values using the validation dataset at the end of each epoch.”
So I guess it doesn’t matter. But how can I plot my confusion matrix if my validation set only consists of 3 classes out of total 6 classes?
Yes, ordered validation won’t cause an issue.
But having only 3 classes is an issue. I will go back to your code again, and that will take some time.
In the mean time, were you able to figure the following out?
I haven’t updated the changes on github yet, is it alright?
I think this issue isn’t as important now since now our direction now is to use an unshuffled validation set for training, so I haven’t given it much thought.
I am only looking at the code I got previously.
Do you know why there are only 3 classes now?
My initial guess is the “split = 0.4” in my code:
validation_dataset = image_dataset_from_directory(directory,
shuffle=False,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE,
validation_split=0.4,
subset=‘validation’,
)
I’m still toying with different parameters in this function!
OK. Let me know what you find. I have actually found the reason, but I want you can find it yourself. I am trying to be a few steps ahead, but I do hope you can catch up or even be faster than me ![]()
I will look at what you find, and give you hint or ask you questions. Although we will finally find a solution togther, I hope to see more effort on your end.

