Oh, I got it. Thanks a million, Raymond. . .
1 Like
Hello! Sorry to disturb you every time.
I built my NN model with Adam (numpy) and now comparing its results with Adam in TF. So, I can get to know whether there is a bug or hyperparameters that led to a poor result.
I don’t know much about TF. Can you please guide me on what mistake(s) I am making in the attached code?

NameError: name ‘kwargs’ is not defined
I’ve one another question in my mind about sine/cosine functions which I will ask after that Adam.
1 Like
It looks like you have just “copy/pasted” the definition of the Adam function as the invocation of that function. Defining a function is a different thing than invoking a function. The first rule is always “believe the error message”, right? Do you see kwargs in your code anywhere? Why is that there and what does it mean?
2 Likes
Yes, I see **kwargs in my code but I don’t know what and why it is, nor do I know much about TF.
1 Like
That is a pure python syntax. kwargs stands for “keyword arguments”. That just means that syntactically you could include more keyword arguments at that point when you call the function. That specific **kwargs token is not supposed to be there on an actual call to the function, which is why that error was thrown. (Well, you could actually create a global variable with that name containing more arguments, but that seems kind of clunky.) The point is we are doing Object Oriented Programming here, right? So a given class may inherit lots of things from its various parent classes and the TF/Keras documentation is usually selective about which arguments they document at a given layer of inheritance. They normally do not include everything possible, since that would get pretty voluminous.
So back to my top level point: it’s a mistake to just “copy/paste” the definition of a function as the invocation of that function. In addition to the kwargs problem, you’re declaring a bunch of default values for all the parameters. Why bother? It defeats the purpose of defaults, but there may be cases in which you want to make it explicit what value is being used just to remind anyone who later comes along and sees the code. But you also may want some of those parameters to be passed in from a higher level, so that way of writing it defeats that purpose. In other words, these are all decisions that you need to make based on what you’re trying to accomplish.
3 Likes
If you’re new to TF, you might want to go on and take DLS Course 2 and Course 4. In addition to all the super interesting and useful material there (ConvNets!), you’ll also get a lot more information about TF and see lots of examples of how to use it.
1 Like
Hello Saif,
I have 2 suggestions:
-
google “kwargs python examples” for some examples / tutorials. It is how I learnt what kwargs (and args) can do.
-
do some experiments and share with us your understanding.
Raymond
1 Like
Saif, actually I welcome you to share with us your findings alongside with your questions. We all don’t stop when a question comes up, but try to gather, distill, and process information (on the internet), then come to *something* and try to verify that *something* with experiments. I hope to see that progress too.
This is not just a place for questions, but you may share ideas too ;). If you organize and write your ideas clearly, you will attract more readers.
1 Like
@rmwkwok readers like me ![]() … I’ve been following every step of this interesting case.
… I’ve been following every step of this interesting case.
1 Like
@Juan_Olano I am also a reader of this topic ![]()
Saif, I look forward to seeing more from your side, not just the questions. ![]()
1 Like
I follow your instruction and get the Ans. “We use *args and **kwargs as an argument when we are unsure about the number of arguments to pass in the functions.” I also know the difference between *args and **kwargs. Thanks, man.
Thanks, @Juan_Olano and @Christian_Simonis for following this chat. I am happy that the Mentors’ eye is on me…
Got this point, sir. I removed them and it ran with no error. My Adam with numpy and Adam with TF show the same result, while poor but it is confirmed that there is no bug in my numpy code. I just need to tune hyperparameters.
I’ve taken the DLS Course 2 but I ignored (or gave less attention to) TF. Because, first, I want to learn everything from scratch and then learn/use any framework… But it was a clever idea from Raymond to compare numpy results with TF. So, I will learn TF.
OK boss…
So far, I learnt that:
- The easiest way to check whether your code has a bug or not is to compare its results with TF.
lr = 0.001(which is a small and appropriate value) but this is not true in all cases. We can and should try0.0001or0.00001or generally 0.001/m.num_iterationsandlrdepend on each other. Smalllr, moreiterationsrequired.- It is not necessary that more the hidden layers, accurate the model. Adding more hidden layers may lead to poor fit. (By the way, I don’t know why this happens).
- Same model (architecture) and the same data may lead to completely different results with normalization and without normalization. So, normalization is necessary.
- Coding in ML is 10 or 20%. The remaining 80% is data preparing, debugging, hyperparameters tunning. . . (Am I right?).
- If Prof. Andrew says
lr = 0.001(or any other default) is a good value, he means generally and not in all cases. So, don’t take it as a universal truth, and explore your own values. - Practicing and experimenting are effective ways to learn more…
- Before posting here, google the issue (StackOverflow is the best).
- You can consider a linear activation function for the last layer (depending on data).
- If there are no negative values in your data, this may not be true after normalization. So, be careful while selecting the activation function of the last layer.
- Hard coding is a bad idea.
I tried to share my learning through this chat (more than 90 replies). I do not mention here the direct learning from courses.
1 Like
I am trying to fit the NN model for the below data:
X = np.random.randint(0,20, size=(1, 1000))
Y = np.cos(X/2)
Both TF and NumPy show the same result which shows that there are no bugs in my code.
I used tanh for hidden and output layers. lr = 0.0000075 and num_iteration = 50000 and got the attached result. Can you guide me, how to improve it, please? I tried different values of lr, num_iterations, and increasing/decreasing the number of hidden layers but no good fit…
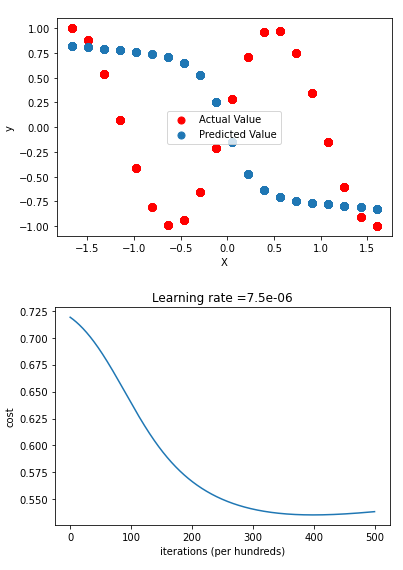
PS: I tried the polynomial and it gives good fit but now I am exploring whether NN can do this task or not.
One more thing. Sorry, I am asking a lot, but Google has no answer for that.
How to determine the accuracy of the regression model? I tried this:
accuracy = (AverageOfPredictionValues/AverageOfRealValues)*100
It doesn’t always work. When the predicted value is higher than the real value, this formula gives high accuracy (even higher than 100) but we know that is not correct.
That can’t be the whole story, based on your graph. It looks like you are doing mean normalization on the x values as well. Are you sure that you are also adjusting your y values accordingly. cosine is a function with well defined behavior, you can’t tell it the output of cos(x) is actually the y value given for the x before it was normalized. That doesn’t make any sense, right? It’ll work if you define y = cos(x) for the normalized x values. But there really shouldn’t be any need to normalize the x values in this case.
What are you using as your loss function? It might shed light to know some of the different network architectures you tried. Do they all give more or less the same results?
1 Like
With a regression problem, the answers can be all over the map, right? E.g. in the housing prices case it could be from 100,000 to 10,000,000 or even more. So it doesn’t really make sense to average the answers. What does that even mean? You need to deal with the differences between the predictions and the real values. You’re using something like MSE as the loss function, right? So you need to use something like distance to measure the accuracy for a single sample:
error = |pred - label|
But then just looking at that as an absolute number doesn’t really make much sense: if the scale is 100,000 to 10,000,000, then a difference of 2 is not very big. But if the scale of the answers is roughly 10 in absolute value, then 2 is a pretty big error. So the usual way to “scale” the error would be to do a variation of the technique you saw in the Gradient Checking assignment in C2W1:
error = \displaystyle \frac {|pred - label|}{|label|}
Then average those values over your training or test set. That gives you the error as a decimal fraction. And the accuracy would be 1 - the error, which you could then convert to a percentage if you prefer it that way.
1 Like
Yes, I normalized X but not Y. I understand your point that “also adjusting your y values accordingly.” So, that is new learning for me that, in case of sine/cosine, either normalized both, X and Y, or don’t normalize any of them.
I tried without normalizing X and got poor fit. I am using MSE loss function.
No. Increasing number of hidden layers led to poorer results than single hidden layer. Also, lr = 0.0000075 led to poorer results than lr = 0.00075. Different architecture and lr values led to different but poor fit.
Aha. Thank you soo much, sir, for the detailed guidance…
I implemented this… But one thing confused me. From the graph (attached), it seems the best fit, but the accuracy is only 77%. Is it normal or am I making a mistake? I also attached my code for the error.

error = (np.abs(AL - Y))/(np.abs(Y))
avg_error = np.mean(error)
accuracy = (1 - avg_error)*100
One more thing: If my Y has zero values which led to 0 in the denominator in the error formula, I add 0.1 with Y. Like this:
error = (np.abs(AL - Y))/(np.abs(Y)+0.1)
Is this the right approach?
PS: The graph I attached with 77% accuracy has no zero values of Y, so, I do not add the 0.1 in the denominator.
Can you share what you have tried in the following table format? You may use 3+2+1(tanh) to represent a NN where the 1st, 2nd and output hidden layers have 3, 2 and 1 neurons respectively, and they all use tanh as their activation functions.
Below is an example.
| trail no. | learning rate | number of iterations | architecture | final training mean squared error |
|---|---|---|---|---|
| 1 | 0.001 | 100 | 3+2+1 (tanh) | 0.02 |
1 Like
Hello! Below is the summary:
| Trail no | learning rate | number of iterations | Architecture | Final error MSE |
|---|---|---|---|---|
| 1 | 0.0075 | 5000 | 7+1(tanh) | 2.556281460632957 |
| 2 | 0.0075 | 50000 | 7+1(tanh) | 2.6742814606329572 |
| 3 | 0.0000075 | 5000 | 7+1(tanh) | 1.7077927051614634 |
| 4 | 0.0000075 | 50000 | 7+1(tanh) | 1.274270730532482 |
| 5 | 0.0075 | 5000 | 7+5+2+1(tanh) | 2.6742814606329572 |
| 6 | 0.0075 | 50000 | 7+5+2+1(tanh) | 2.6742814606329572 |
| 7 | 0.0000075 | 5000 | 7+5+2+1(tanh) | 1.9298783088820315 |
| 8 | 0.0000075 | 50000 | 7+5+2+1(tanh) | 1.340751030629376 |
I used this equation for final training mean squared error.