Hi team,
I have a question regarding the following slide:
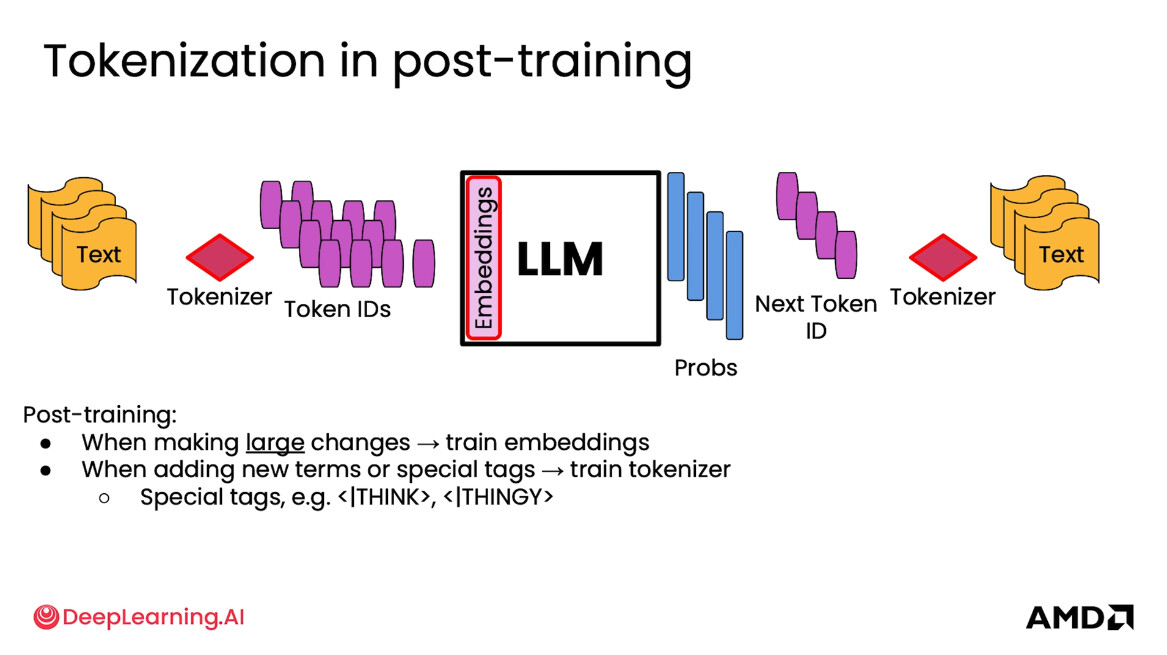
I got confused about the statement “train tokenizer” in the context of post training. Is that really a thing? Wouldn’t that alter existing token IDs and thus make the existing embeddings unusable? I know that it’s always possible to manually add new tokens to a tokenizer / LLM, but the term “training” confuses me. If it refers to a specific technique, I would appreciate if you could provide a brief reference. Thank you!