Are the x variable features and the m variable(total number of training sets) always the same? I just watched this video on Linear regression for the course and Dr. U mentions that m is tha total number of training sets. However, would not m and x be the same since x will usually match the number of rows in a dataset. I am leaning to “no they are not the same”, but would love an explanation as to why. Thanks in advanced. My theory is that there may be some bad inputs?
Hi there,
I assume you mean `m: the number of training samples‘.
In addition you also have dimension of your feature space, e.g. when you predict housing prices, possible features can comprise following dimensions:
- area in m^2
- age of house
- …
Both dimensions (dimension of feature space as well as number of samples) are important and determine the size of your feature matrix:
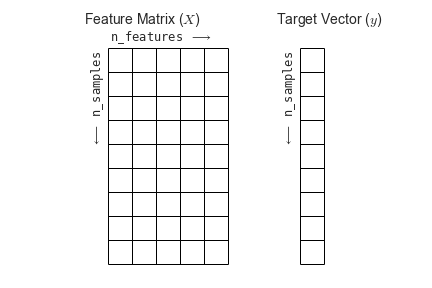
More information can be found here:
https://jakevdp.github.io/PythonDataScienceHandbook/05.02-introducing-scikit-learn.html
Hope that helps!
Best regards
Christian
I tend to think of this in terms of axes and shapes of the data. The m here represents the number of observations that we’re dealing with. It is the leftmost (outermost) axis and represents the number of rows we have. This is also known as the batch axis. Moving to the right, the next axis is the feature axis, which in the lectures has n elements. Since we are dealing with linear regression, the number of elements in this axis also affects the shape of w, since we are working on f_wb(x) = wb + x. Since this axis has n elements, and the previous one had m elements, the total pieces of information are m*n, hence the grid. Sometimes you will see a third axis, when each piece of data is treated as a vector instead of as a scalar. I find adding this third axis for tabular data makes the code cleaner, and the intent explicit. For example, a string should be treated as a scalar since you can’t put it on an “axis”, I think of the intercept in the same way, as a scalar since there is only one at a time. One of the neat things that happens when the shapes of things are very clear is that the dimensions of things line up well. For example, w = w - alpha*dj_dw, here alpha is a scalar, w is a vector, so the shape of w has to be the same as the shape of dj_dw, and similarly with dj_db. This also helps with using the dot product as the shapes need to line up correctly for it to work.
Hope this helps!