What is the key difference in terms of Architecture/blocks and technically between Encoder and Decoder blocks in Transformers [Attention is all you need paper.
Multi headed attention: Does it mean 512 embedding sequence is broken down into smaller chunks which equals number of Multi heads and then Q,K,V operations are done on these chunks and then concatenated at last?
Hi!
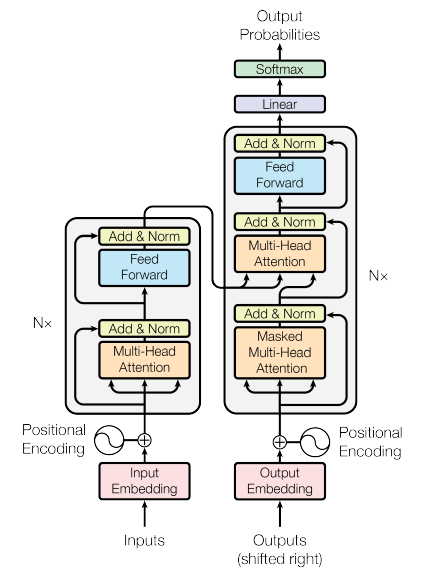
According to the paper, as you can find below, the key differences between the encoder and decoder are:
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. ArXiv. /abs/1706.03762
-
Number of Sub-Layers:
The encoder block has two sub-layers (self-attention and feed-forward).
The decoder block has three sub-layers (masked self-attention, encoder-decoder attention, and feed-forward).
-
Attention Mechanisms:
The encoder block uses only a self-attention mechanism.
The decoder block uses a masked self-attention mechanism and an additional encoder-decoder attention mechanism.
And you are correct about the Multi-Head Attention Mechanism. The projected Q, K, and V matrices are split into multiple heads. For instance, with an embedding dimension of 512 and 8 heads, each head will have a dimension of 64. The output of all the attention heads is combined to form a single matrix.
Feel free to reach out if you encounter any further issues. Happy learning!
2 Likes
Thank you so much @XinghaoZong
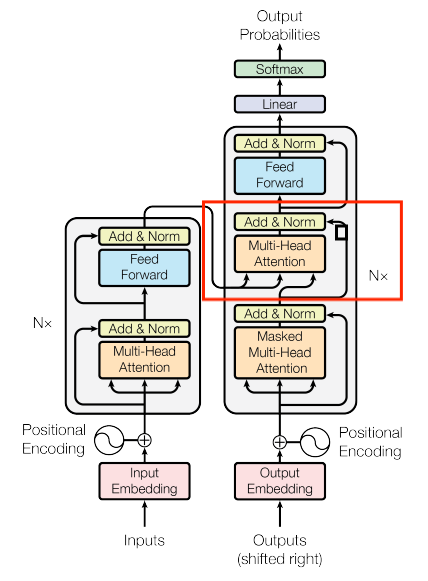
What is that extra additional encoder-decoder attention mechanism.? What is the functionality of it and why its required? Where its coming from?
Hi! This is the encoder-decoder attention block.
The whole decoder is responsible for generating the output sequence and needs to attend both to its previously generated tokens (via masked self-attention) and to the encoder’s output (via encoder-decoder attention). The additional encoder-decoder attention mechanism allows the decoder to incorporate information from the entire input sequence while generating each token.
Feel free to reach out if you encounter any further issues. Happy learning!
2 Likes