I’m currently working on building a deep-learning model, specifically using an LSTM network, for regression decoding. The challenge I’m encountering lies in the nature of the data available for regression. The data consists of single-trial instance wherein the labels follow a time-course pattern of initial increase followed by a decrease, occurring almost once within the trial. You can visualize these labels in the first figure provided below. Each time sample of labels is associated with neural signal data, which can be conceptualized as a high-dimensional signal consisting of 32 features.
My question pertains to the appropriate division of the dataset into training, validation, and test sets. I aim to ensure each set contains sufficient representation of the data while avoiding the issue of providing the network with future data during training, only to test it on past data. For instance, one approach could involve training the model on data from time step 5000 onwards and testing it on data from time step 0 to 5000. However, this presents a risk of data leakage.
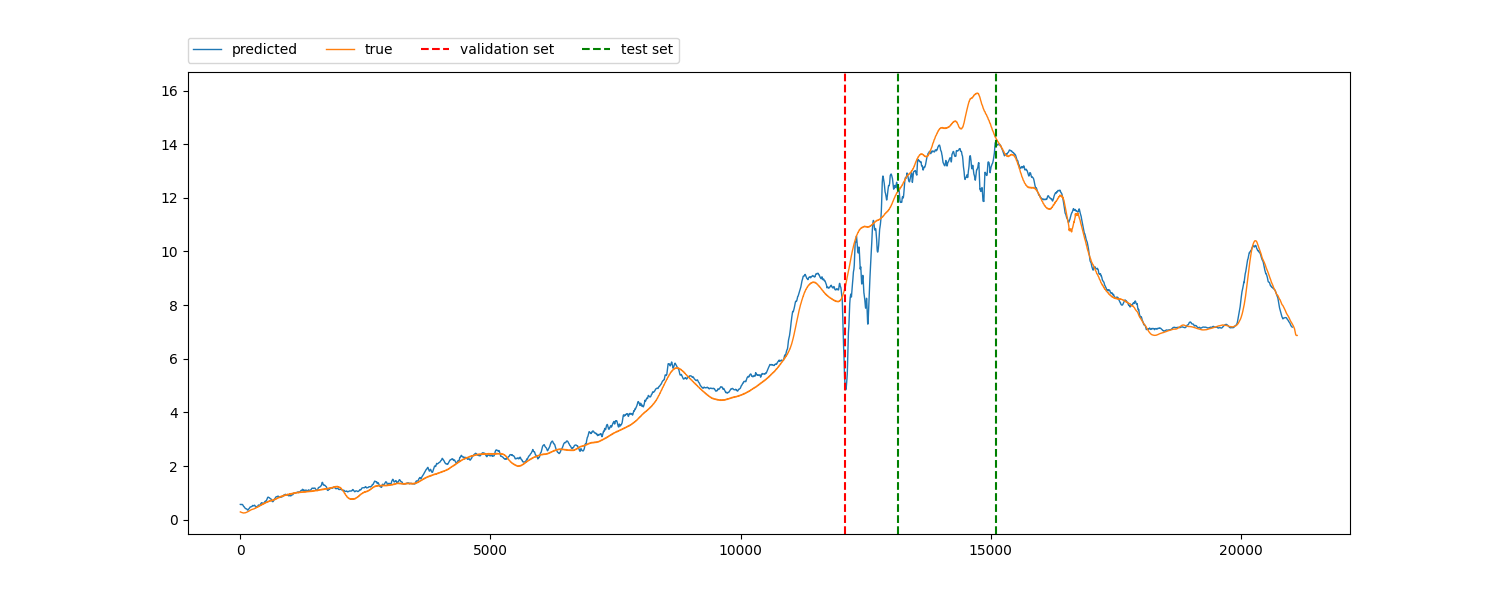
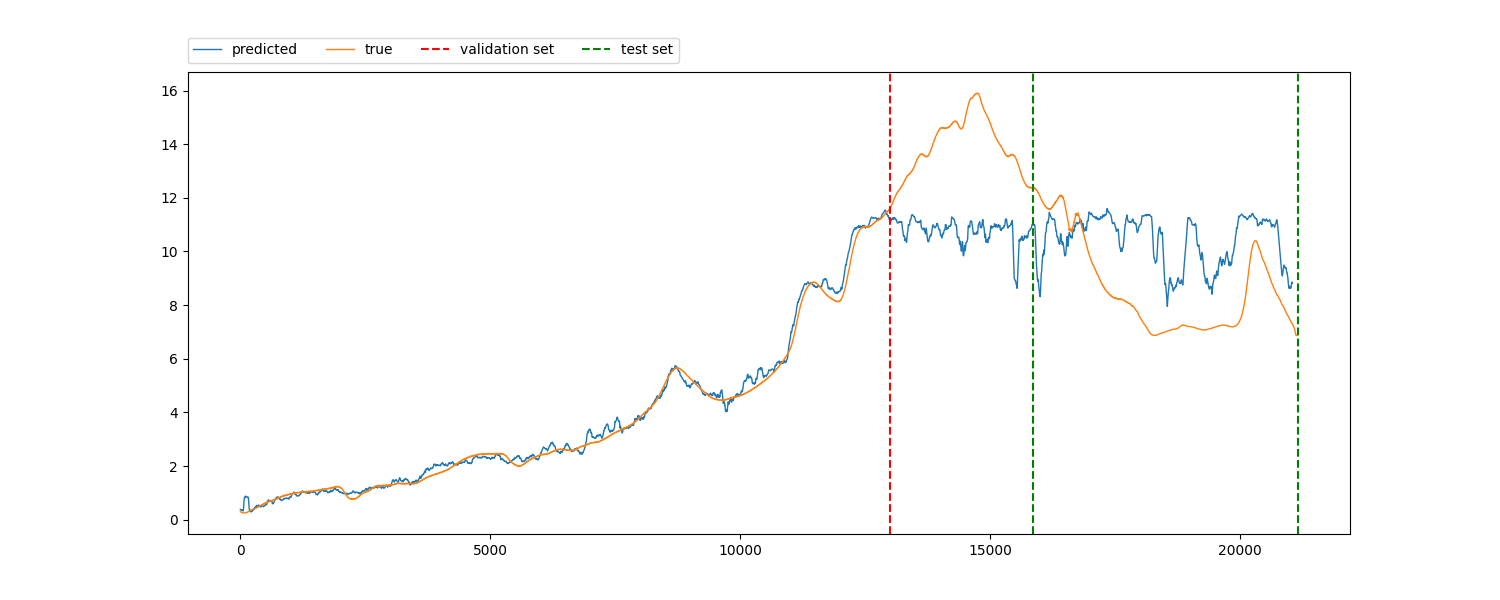
In the second figure, you can observe the results of my regression analysis depicted by the blue line. The data was divided into multiple folds, with the validation and test splits indicated by vertical dotted lines. My objective is to validate the model’s efficacy in capturing the ramping behavior of the labels without encountering data leakage. However, employing the conventional approach of splitting the data into consecutive X percent for training and Y percent for testing (e.g., 70-30 split) seems to yield a model that struggles to make accurate predictions. The outcome of this prediction is illustrated in the third figure. Is the bad outcome of the third figure, compared with the second, and indication that in the second I’m just overfitting on the data with a data leackage? If not, how can I verify this?
I’m seeking insights on how best to handle this question. What techniques or approaches would you recommend to address this challenge effectively?
Your suggestions and expertise would be greatly appreciated.
Sorry @TMosh, perhaps I wasn’t clear in my initial question (which I have since edited). The first figure illustrates the labels of the dataset, representing the expected output. The input, on the other hand, consists of neural signals comprising 32 features for each time step. I need then a non-linear method, like deep-learning, for modeling it.
It looks like some kind of sequence model (RNN, GRU, LSTM) is probably the type of network you need.
But I don’t really understand your situation well enough to say more than that.
E.g. It sounds to me like you’re saying you literally have just one sequence of data, meaning a single “sample”. And what you’re trying to do is divide that one sample sequence into segments and use the first segment as training data, the second as cross validation data and the third as test data. If I’ve got that right, I would be very doubtful that would work. Neural Networks of any architecture typically take quite a lot of sample data in order to be trained successfully. How can you be sure that in your one sample that you see all possible patterns that the model needs to recognize in the first 13000 time intervals?
@TMosh@paulinpaloalto yes, I’m using a sequence model (i.e. LSTM) for obtaining the predictions.
I’m working with a dataset of dimensions 22,000x32. For each of these 22,000 data points, I need to predict a single value within the range of 0-16, as depicted in the first figure of my initial post.
The challenge I am encountering is on the proper division of this dataset into training and test sets. The value to be predicted does not repeat frequently within the dataset; rather, it exhibits an overall pattern of increasing from 0 to 16 within the first 15,000 points, followed by a predominantly decreasing trend.
I have explored one approach, namely cross-validation, to address this challenge. In this method, I partitioned the dataset into several folds for testing, with each fold utilizing a different consecutive portion of the dataset as the test set. For instance, the first fold comprised the first 20% of the data as the test set and the remaining 80% as the training set, while the second fold used data from the 20% to 40% range as the test set, and so forth. This approach has shown promising results, with high accuracy observed in the test sets across all folds, as depicted in Figure 2 for one fold. However, I am cautious about potential overfitting, particularly due to the risk of data leakage between the training and testing partitions.
I think that I have enough data to train an RNN network on this dataset, and my question revolves around the appropriate partitioning of the dataset to ensure an unbiased evaluation of the model’s performance, if an appropriate partitioning method does exist.
Thank you for your attention and assistance on this matter.
Sorry, but I still must be missing something here. So what patterns are you trying to learn? Is it patterns that are expressed within smaller time ranges of your data? Or is it the entire sweep from 0 to 16 and back down? If you need your model to predict both the increase and the decline, then how is that going to work if you cut off your training portion of the data at 13,000? Then you miss the peak and the decline, right? There are a couple of smaller peaks, but those don’t result in a continuing decrease, so there must be something special to be learned about what is happening from 14,000 to (say) 18,000.
So I have to believe that I’m just missing your point.
The answer is the entire range from 0 to 16 and back.
Perhaps the resolution to my query is that there isn’t a suitable method for effectively dividing the dataset for training and testing. Additionally, I am wondering whether cross-folding partitioning between training and testing portions could be deemed acceptable, or if there are alternative approaches to address this issue.
Yes, if you need your model to learn the entire range of behavior shown in the original graph, then it seems plausible that there is no way to train the model on a subset of that data. So what you need to make this work is a number of samples that cover the entire range, instead of just one sample that you can subdivide.
At least that would be my analysis, but that is based on no other knowledge of the meaning of your data. Is there some physical phenomenon driving this? Are there potentially other inputs besides the numbers in the sequence?
Okay, I’m concerned that when presenting the results, which will include the prediction error for each subset of the dataset not used for training, someone might suggest that the good predictions are merely due to data leakage. I think I would say the same. That’s why I was asking.
Explaining the nature of the data concisely in a post is challenging. Essentially, the data originate from recordings of a neurophysiological system, with the behavior characterized by the labels in my dataset (ranging from 0 to 16). The hypothesis I aim to confirm is whether could exist a model that given the neurophysiological system input can predict the outcome of the behavior. If I can construct an LSTM model that accurately predicts it, then the answer would be affirmative.
Well, suppose you had 100 complete samples that cover the full range. Then you divide them into three completely distinct sets: say 80 for training, 20 for cross validation and 20 for testing. They are all different and there is no “data leakage” between them, right?
Well, then doesn’t it make sense that you’ll also need the readings of those inputs? If I’m correctly understanding what you just said, then it means that you’re taking an incorrect view of the actual problem at hand here. You’ve only showed us the outputs. The model needs to learn how to predict the outputs based on a combination of the inputs and the previous outputs. That’s how RNNs work, for example.
Have you taken Course 5 of DLS about Sequence Models?
Yes, I only have one example of the complete dynamics of the system generating this dataset. Nevertheless, I anticipate some level of generalization in the dynamics that govern the outcomes. That’s why I attempted to fit a model to these data regardless.
In the scenario you’re describing, I agree with you, but mine is different. I have a dataset of 100 samples, and I’m dividing it into several folds of 80 for training (e.g. from sample 0 to 20, and then from 40 to 100), and 20 for testing (e.g. the remaining samples from 20 to 40). Consequently, I’m encountering data leakage because I’m testing the model on unseen data (from 20 to 40), while I included the dynamics from 40 to 100 during training.
I haven’t taken the DLS course, but I’ll look into it. Considering including previous system outputs in the prediction is a good idea, but my main question was about organizing the dataset, rather than which method I should use for a better prediction. Based on your responses, it seems that building a regression model isn’t feasible, and I would need another dataset with additional dynamics.
To illustrate my situation with an analogy: Imagine conducting an experiment where you aim to predict a person’s heart rate based on pupil dilation measurements (it’s just a random idea to explain the nature of the problem). During a one-minute recording, you observe both variables while the person’s heart rate increases and decreases due to exercise. Then, you only have one instance of heart rate fluctuations.
Now, you want to create a model that predicts heart rate based on pupil dilation. This model could utilize LSTM and incorporate past pupil dilation values and predicted heart rates. However, how would you evaluate its effectiveness? Is it a mistake to divide this dataset into multiple folds? Is this problem unsolvable?
Thank you for your valuable insights and suggestions.
Yes, it is definitely a concern that you’ll have data leakage problems if your approach is to take just one sample series of data and then “slice and dice” it to create your training and test data. So don’t do that.
I think you are fundamentally missing a crucial point in all this: machine learning requires a lot of data samples in order to learn the patterns. No, as a general matter the problem is not unsolvable, but it may not be cheap or easy to solve. Taking your heart rate and pupil dilation example, why would you assume that just running the measurements once on one person is determinative? Are all people the same in that respect? I’m guessing not, but I’m not a biologist. Or how about the same person with or without coffee? Or how about the same person at 8pm as opposed to 8am? Or the same person after an interval training workout as opposed to after watching TV or meditating or sitting quietly in a dark room for half an hour?
So the point is: run the experiment a lot more times and then you have more independent data.
Sorry, one more thought to add to the mix: maybe your case is one in which the results of one experiment actually are determinative. But in that case, my claim is that machine learning is the wrong approach to the problem. If one series of data is determinative, then you’ve got a physics problem, not a machine learning problem. You need to invest the effort to understand the physical laws that are in play. ML/DL is not good at solving physics problems in general.
Note that in my use of the term “physics” above, I’m considering that chemistry and biology are just physics “writ large” as it were. It’s all just fundamental particles interacting according to the various laws of physics.