For batch normalization on mini-batch of size 1, or a very small batch size, we aren’t doing any meaningful averaging. But it still works in practice. Can you give me an idea of why ?
Hello @ultimateabhi,
I was wondering how you would define “it works”. Any of the below?
- Can run without errors.
- Can train a NN without much performance drop.
- Can train a NN with huge performance boost.
For 2 & 3, I would expect you had observed some experiment results that support them.
Let’s see where we should focus on for the discussion.
Cheers,
Raymond
@rmwkwok : I would define “it works” as Can train a NN without much performance drop.
Since for some large models GPU memory constraints sometimes force people to keep the batch size at 1. In this case the model still trains, and gives some sensible results. But it shouldn’t because \tilde{z} = \beta and hence we are loosing all information about the data sample in the process!
…I am talking about the implementation of batch norm in Pytorch. Do they do something other than averaging over samples ?
@paulinpaloalto : Thank you for moving the thread. I understand mini-batch size 1 is pretty much useless, but my use case is when you can’t fit a larger model on your machine. In that case the normalized values will become trainable parameters completely,
Great. Would you mind do a small and quick experiment? If you instantiate a batchnorm object of your interest, and pass through it a mini-batch of 1 sample with the shape of your interest, what does the sample look like before and after? It would be great if you can also share the code here so that I can reproduce it on my machine.
I would expect the code to be less than 5 lines?
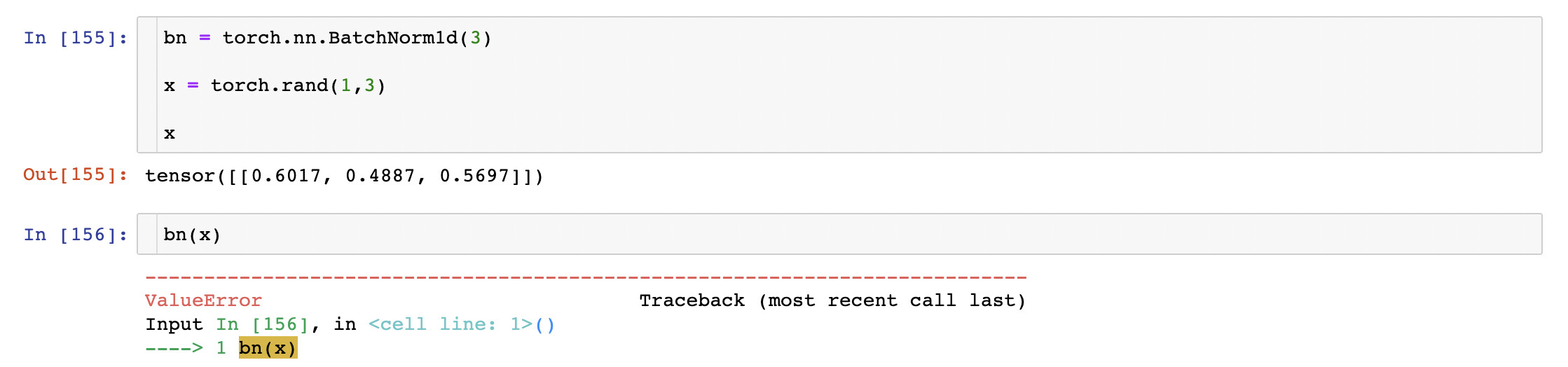
That is not a problem @ultimateabhi ![]() Thank you for your inspection works!
Thank you for your inspection works!
Cheers,
Raymond