Hello! I just finished watching the 5 minute lecture on Logistic Regression in Week 2 of the Neural Networks and Deep Learning Course. In this lecture, prof. Andrew NG explains why linear regression is unsuitable for solving binary classification problems and says that logistic regression should be used instead.
He explains that given an input to the classifier, the output should be a probability value in the range of 0 to 1. Since the output value of the Linear Regression hypothesis function can be negative and also much greater than 1, it is not a good choice for Logistic Regression.
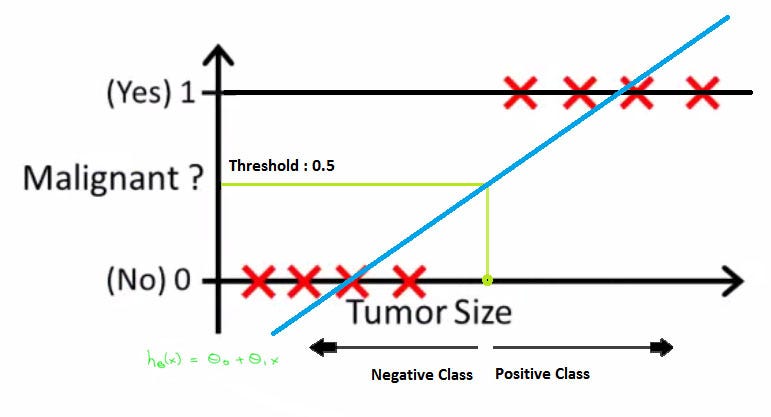
However, after the Linear Regression hypothesis function gives an output for a given input, can’t we take a threshold of say 0.5 and then change the output value to either a 0 or a 1 depending on whether it is lower or higher than the threshold? For example if the function outputs a value -241 then we can take it as 0 but if it outputs 0.51 or 210 then we can take the output as 1.
When I researched about this on the internet, I got the answer to my query. However that has landed me into another query. I understand that Linear Regression cannot be used with a threshold because a threshold of 0.5 may work for a dataset in the below link.
Can’t we take threshold as a hyperparameter and then algorithmically find the threshold value that results in the highest training set accuracy after we have fit our Linear Regression Model?
Hello Rashmi. Thanks for the reply! However I still have a query.
The thread you linked to mentions that linear regression is not apt for classification and that it can output values below 0 and above 1 as well which is undesirable. However, in my question I have mentioned that if we take care of all those caveats, then why can’t we use linear regression?
While doing a linear regression, we usually find parameters in the form: a1, a2…till a(n) such that they define the n-dimensional plan as: a1 x1 + a2 x2 + a3 x3 +…+ an xn + b = 0. This fits the n-dimensional data. Of course, not all data are linearly separable, so we try to find with different neural networks that can create much more complex decision boundaries. In the given figure, you can have an idea how linear and logistic regression works:
In the case of logistic regression, it tries to find a hyperplane in the input space (one of the best explanations provided by Paul sir), logistic regression in the neural networks makes a clear-cut demarcation between what is True and what is not True. (for example: in the case of a spam mail; it defines whether the mail is spam or not).
Here, we are doing this calculation for factors like coefficients and bias for a given linear transformation that gives us the minimal cost. Thus, we can express the entire equation including the coefficient and bias for a logistic regression as w.T\dot x + b = 0.
But, when the data is not linearly separable, logistic regression doesn’t work appropriately. In that case, we try doing polynomial expansion of the data at the first place and then we perform the logistic regression over the expanded data. Thus, data plays a very significant role in every manner, as there is no such guarantee that after performing this process, we would get a profound hyperplane that could divide the samples in asked format.
Hello Rashmi. Thanks for replying! I truly appreciate your effort and I apologize for any inconvenience caused from my side. However I still have a query.
I totally agree with you about how logistic regression is well suited for classification since it can find a hyperplane that can make a clear demarcation between what is True and what is not.
I also agree that linear regression might not be well suited for a classification task due to several reasons. I have mentioned those reasons as well in my initial question.
However, if we solve all these problems is it possible for linear regression to be suitable for classification? The solution to the problems has been proposed below by me.
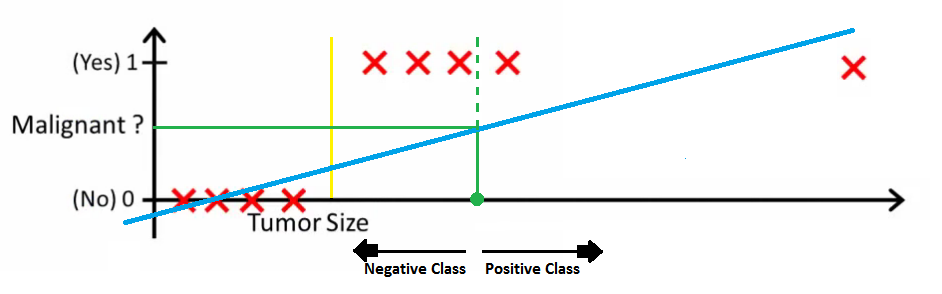
Well, yes, you can apply threshold as a parameter in linear regression models for classification purposes with the use of Threshold Regression Models. Below is a pictorial representation on how applying threshold could change the graph of a linear-no threshold model.
The author considers two approaches for finding the maximum likelihood estimate of the threshold model parameters: exact and smooth and four kinds of threshold effects. Well, it’s a good read for those who are interested in finding out how setting threshold as a parameter could have an impact on the values.



{kind=link}
{kind=link}