Among the 5 categorical features in the heart.csv dataset:
.
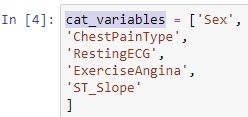
there are 3 continuous value features:
- RestingBP
- Cholesterol
- RestingECG
- MaxHR
- Oldpeak

The categorical features have been taken care of with one-hot encoding - pd.get_dummies.
The continuous value features are used as is in the model and during the training.
Shouldn’t the continuous value features be split as mentioned in the lecture Continuous valued features? I guess that, for example, the level of cholesterol can have some impact on the hart disease.
Am I missing something, seeing something wrong?
Thanks