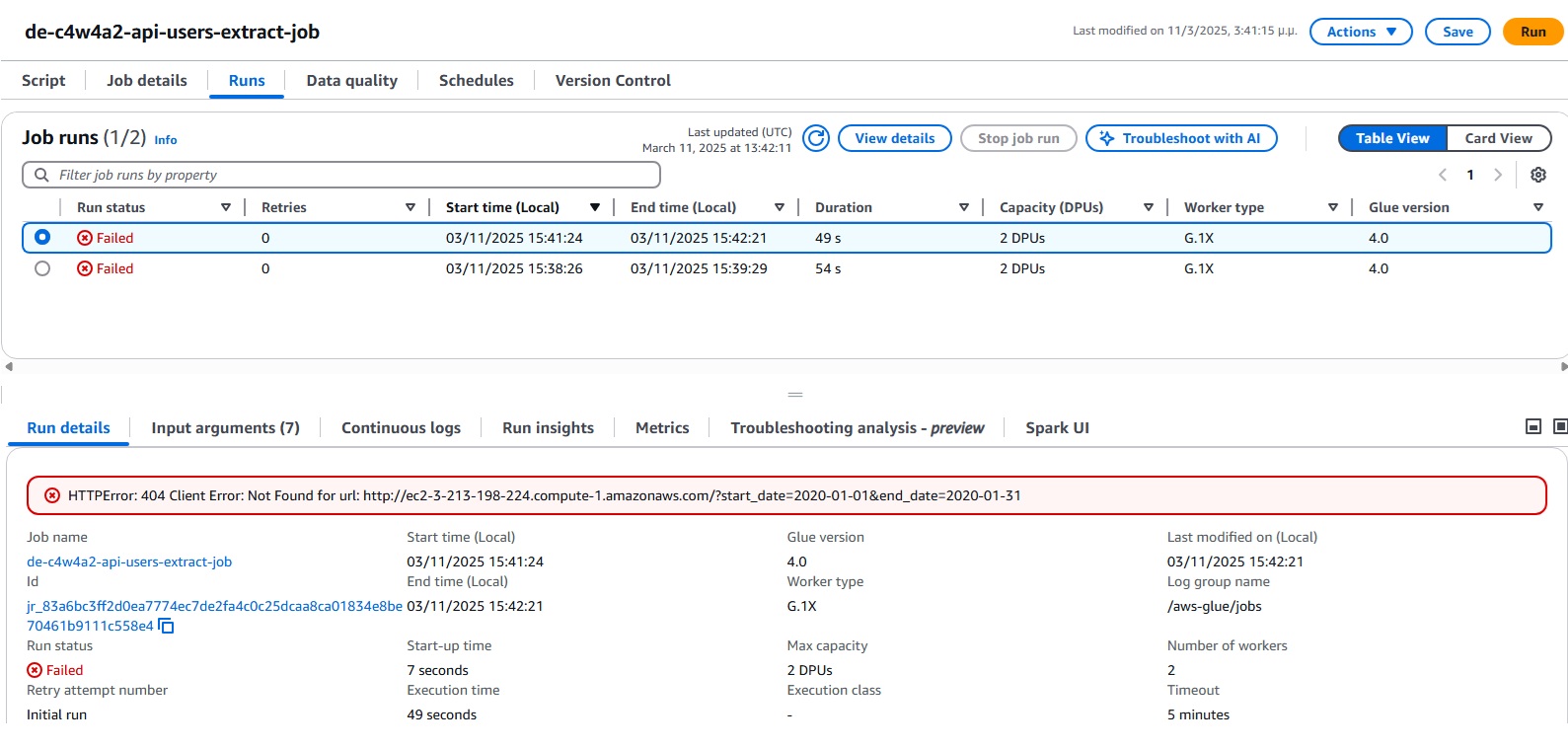
now I am getting this error
resource “aws_glue_connection” “rds_connection” {
name = “${var.project}-connection-rds”
At connection_properties, add var.username and var.password to the USERNAME and PASSWORD parameters respectively
connection_properties = {
JDBC_CONNECTION_URL = “jdbc:postgresql://{var.host}:{var.port}/${var.database}”
USERNAME = var.username
PASSWORD = var.password
}
At the physical_connection_requirements configuration, set the subnet_id to data.aws_subnet.public_a.id and
the security_group_id_list to a list containing the element data.aws_security_group.db_sg.id
physical_connection_requirements {
availability_zone = data.aws_subnet.public_a.availability_zone
security_group_id_list = [data.aws_security_group.db_sg.id]
subnet_id = data.aws_subnet.public_a.id
}
}
Complete the resource "aws_glue_job" "rds_ingestion_etl_job"
resource “aws_glue_job” “rds_ingestion_etl_job” {
name = “${var.project}-rds-extract-job”
Set the role_arn parameter to aws_iam_role.glue_role.arn
role_arn = aws_iam_role.glue_role.arn
glue_version = “4.0”
Set the connections parameter to a list containing the RDS connection you just created with aws_glue_connection.rds_connection.name
connections = [aws_glue_connection.rds_connection.name]
command {
name = “glueetl”
# Set the value of scripts_bucket and “de-c4w4a1-extract-songs-job.py” for the script object key
script_location = “s3://${var.scripts_bucket}/de-c4w4a1-extract-songs-job.py”
python_version = 3
}
At default_arguments, complete the arguments
default_arguments = {
“–enable-job-insights” = “true”
“–job-language” = “python”
# Set "--rds_connection" as aws_glue_connection.rds_connection.name
“–rds_connection” = aws_glue_connection.rds_connection.name
# Set "--data_lake_bucket" as var.data_lake_bucket
“–data_lake_bucket” = var.data_lake_bucket
}
Set up the timeout to 5 and the number of workers to 2. The time unit here is minutes.
timeout = 5
number_of_workers = 2
worker_type = “G.1X”
}
Complete the resource "aws_glue_job" "api_users_ingestion_etl_job"
resource “aws_glue_job” “api_users_ingestion_etl_job” {
name = “${var.project}-api-users-extract-job”
role_arn = aws_iam_role.glue_role.arn
glue_version = “4.0”
command {
name = “glueetl”
# Set the value of scripts_bucket and "de-c4w4a1-api-extract-job.py" for the script object key
script_location = “s3://${var.scripts_bucket}/de-c4w4a1-api-extract-job.py”
python_version = 3
}
Set the arguments in the default_arguments configuration parameter
default_arguments = {
“–enable-job-insights” = “true”
“–job-language” = “python”
# Set "--api_start_date" to "2020-01-01"
“–api_start_date” = “2020-01-01”
# Set "--api_end_date" to "2020-01-31"
“–api_end_date” = “2020-01-31”
# Replace the placeholder with the value from the CloudFormation outputs
“–api_url” = “http://ec2-3-210-55-215.compute-1.amazonaws.com/”
# Notice the target path. This line of the code code is complete - no changes are required
“–target_path” = “s3://${var.data_lake_bucket}/landing_zone/api/users”
}
Set up the timeout to 5 and the number of workers to 2. The time unit here is minutes.
timeout = 5
number_of_workers = 2
worker_type = “G.1X”
}
Complete the resource "aws_glue_job" "api_sessions_ingestion_etl_job"
resource “aws_glue_job” “api_sessions_ingestion_etl_job” {
name = “${var.project}-api-sessions-extract-job”
role_arn = aws_iam_role.glue_role.arn
glue_version = “4.0”
command {
name = “glueetl”
# Set the value of scripts_bucket and "de-c4w4a1-api-extract-job.py" for the script object key
script_location = “s3://${var.scripts_bucket}/de-c4w4a1-api-extract-job.py”
python_version = 3
}
Set the arguments in the default_arguments configuration parameter
default_arguments = {
“–enable-job-insights” = “true”
“–job-language” = “python”
# Set "--api_start_date" to "2020-01-01"
“–api_start_date” = “2020-01-01”
# Set "--api_end_date" to "2020-01-31"
“–api_end_date” = “2020-01-31”
# Replace the placeholder with the value from the CloudFormation outputs
“–api_url” = “http://ec2-3-210-55-215.compute-1.amazonaws.com/”
# Notice the target path. This line of the code code is complete - no changes are required
“–target_path” = “s3://${var.data_lake_bucket}/landing_zone/api/sessions”
}
Set up the timeout to 5 and the number of workers to 2. The time unit here is minutes.
timeout = 5
number_of_workers = 2
worker_type = “G.1X”
}
This is the error