Hi Alex,
Bias and variance can relate to the model prediction and can be on any part of the data - training, validation or test set. It just means what kind of error you are seeing in your predictions w.r.t to the actual data.
Let’s take a simple example, assume the actual value are the red dots in the center in the below image and the blue dots are the predictions, there are four possible scenarios:
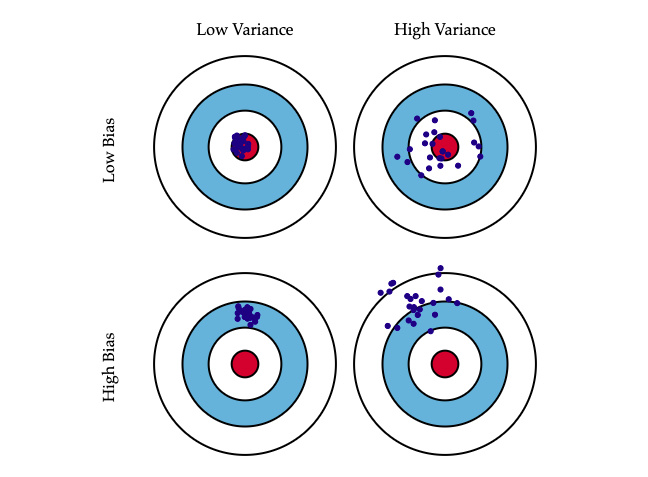
Image source: https://scott.fortmann-roe.com/docs/BiasVariance.html
-
Top left: Low bias - low variance: The model predictions matches more or less consistently with the expected value.
-
Top right: Low Bias- high variance: There is a large error in the model predictions, while it does get some of the expected values correct, but often misses the target by a large value. Also, another thing to note is that the error distribution is roughly symmetric, i.e. there are roughly as many predictions which are below actual value as there is above the actual value.
-
Bottom Left: High Bias and low variance - the model output doesn’t vary much but is very far from the expected value.
-
Bottom Right: High variance - high bias: the model is completely off the mark and the output also has a lot of variations.
Below shows how model complexity affects variance and bias. Simple models like linear regression/logistic regression tend to have low variance but high bias while more complex models like deep neural networks tend to have a low bias but high variance (again, this is dependent on the dataset you are using for the model, for some simple datasets with linear relationships, linear regression is good enough and it’ll have a low bias and variance).
Image from: https://www.researchgate.net/publication/335604816_Artificial_Intelligence_and_Machine_Learning_in_Pathology_The_Present_Landscape_of_Supervised_Methods
Similarly in neural networks, a model with fewer parameters (fewer layers for e.g.) will have a comparatively higher bias but lower variance while a model with more parameters will comparatively have a higher variance but lower bias.
If you are training a deep-learning model from scratch, initially the major contributor of the prediction error is bias, but as the model trains more and more, beyond a point it overfits (it is now starting to learn extraneous information in the data like noise) and the proportion of variance in the error increases.

image source: https://medium.com/@rahuljain13101999/why-early-stopping-works-as-regularization-b9f0a6c2772
So, what you said is partially correct, since the proportion of bias in the error is higher in the initial training period, checking the error in training set is a good indicator of bias (and thus underfitting). But as you keep training the model further and further, the error in training set will keep reducing (as beyond a point, the model is now overfitting and probably also learning noise patterns now) but the error won’t be obvious in the training set anymore, but the error in validation set will shoot up, so high variance error is easier to catch in the validation set. But, on it’s own, bias and variance definition is not tied to training set/validation set/test set.
Hope this helps.
Also, there are multiple questions on the same/similar topic in the past, you can check the responses to them: Search results for ‘bias variance’ - DeepLearning.AI.

