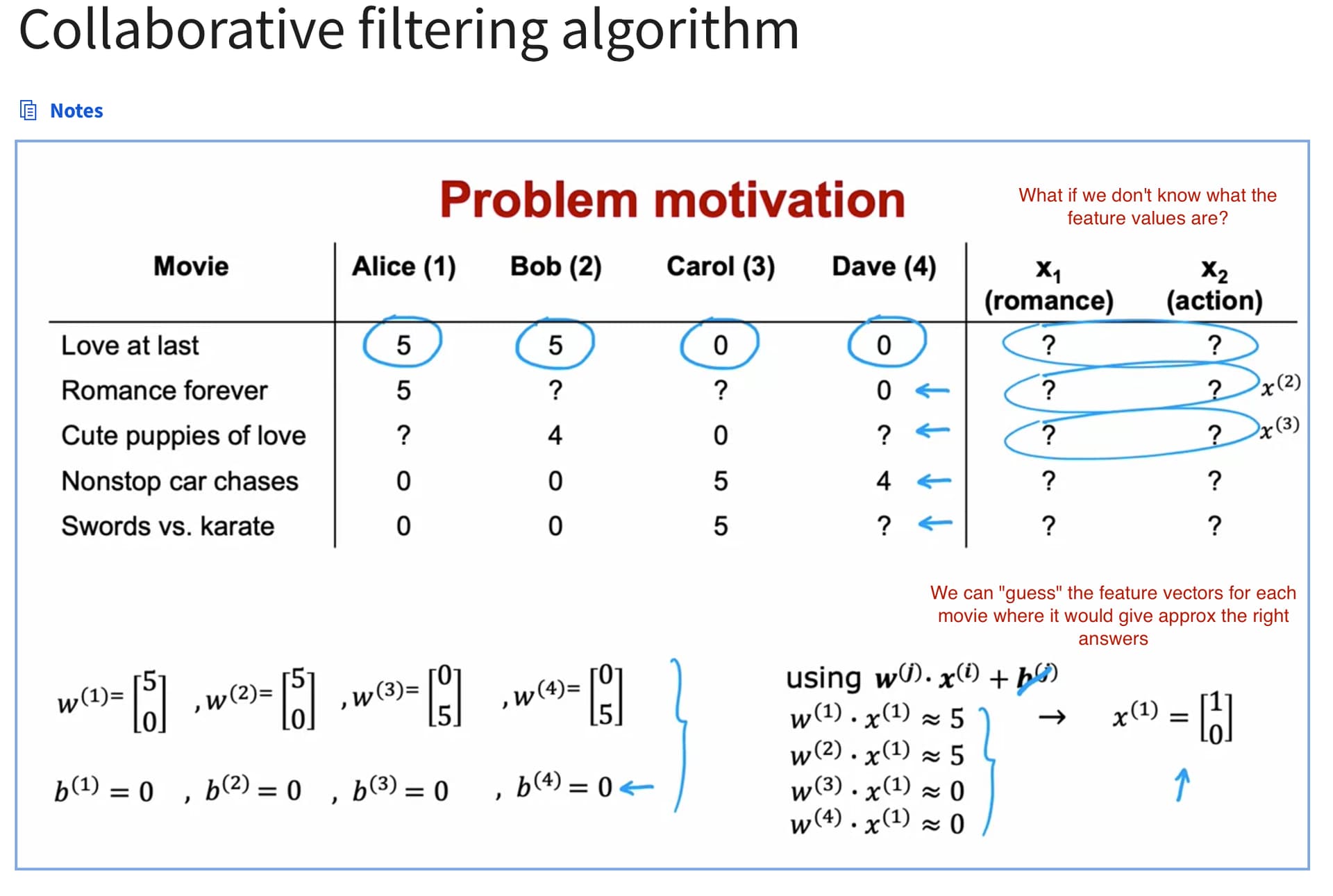
The Collaborative filtering algorithm is very interesting!
With features “romance” and “action”, well the algorithm doesn’t actually know what makes a movie a romance movie or an action movie, and those labels could have been “apple” and “pear” and it would do just as well (if I understand correctly).
If this is true, then it is really grabbing two “signals” to fit, and we don’t know if it’s using “romance” and “action” or something completely different that we haven’t thought of (to fit to the users collaborative ratings) … is this correct?
Yes, I agree with you that, the algorithm does not necessarily extract exactly the “romance” and “action” components from the data with many movies. It could have been a composite feature with 71% romance and 10% action 19% family , and another feature composite of movie length, director popularity and so on. We can’t actually very accurately explain the meaning of the features extracted - they can be anything. However, “romance” and “action” are meaningful examples of what are possibly extracted because they are shared by all five data samples.
If we’re not sure what it’s using, that means we could use, say, 10 features (x_1 to x_10) and let it do its “magic” - or would there be a danger of overfitting?
Thank you, and sorry I’m still trying to see if I understand correctly … so it might pick up that a group has a very particular taste in movies that we can’t easily classify as a genre.
For example, I enjoy some comedy movies, but others drives me up the wall (comedy tends to be very individualistic and there are lots of different types).
It might pick up that I enjoy comedy with lots of word-plays, but not sit-coms or slap-stick, but it also has to have some sort of romance in there too (eg at least 10%), and swearing to R16 level is ok but not R18, and it better not have actor XYZ in there as I don’t like them, and a twist is good but not necessary, and it has to have a happy ending, and the list goes on…
I’m not trying to be controversial here, but might it also pick up that someone likes movies that are racist or sexist - and recommend them to that person - is that right?
Let’s say that your taste (described by the long list of factors) is completely reflected in a feature x_52, which means that a movie that is completely your taste will see x_52 = 1 . However, for this variable to be “trained out” in the first place, I am afraid there have to be a significant number of people or a majority of people exactly like you or very much similar to you in the dataset for this variable to stand out. The features are extracted from all users and movies as an effective representation for everyone and every movie, so i won’t be surprised that no single taste will see an individual feature to be trained out just for it.
So,
yes, a feature is a mix of many factors that we can’t easily classify as a genre
it’s highly unlikely that there will be a feature that fits one person, unless the majority is a group of people who share the exact same taste - which is a very weird world.
as you said, the algorithm doesn’t know anything about racist or sexist, and if we include those kinds of movies into the dataset, then they can be recommended as well, but we won’t know whether the movies are recommended because they are racist or not. The only way to make sure they are not recommended is by filtering them out either from the training dataset or from the prediction result.