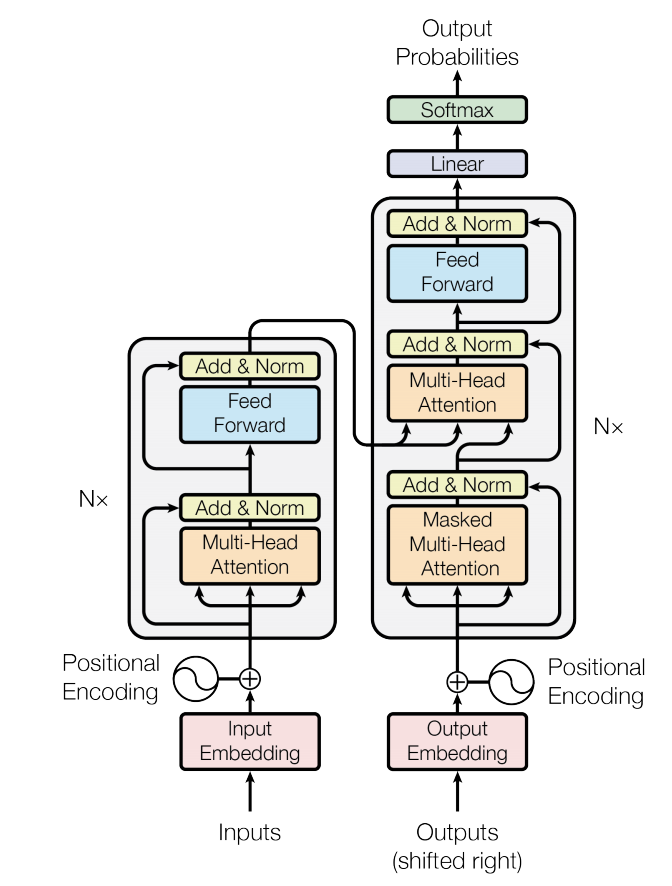
It seems the W2 summarization model works only on the decoder and there is not encoder part of the model? And the W3 Bert model has both the encoder and decoder included, am I correct?
What determines whether an encoder is needed or not? Also it is not clear in the W3 model how the encoder will feed into the decoder to guide the cross attention. Can you help explain?
That is correct, this assignment uses the decoder-only approach for summarization.
That is false. Bert is the encoder only.
Usually, the performance you achieve. You can try both approaches and see what is best for you (computation wise, accuracy, etc.).
Usually, the summarization is done with encoder and decoder transformers (not like the one in the assignment). In that case (encoder-decoder) the encoder gets the input of the text, and the decoder outputs only the summary part.
In C4W1, we were presented with the encoder-decoder translation, where English text was input for the encoder and German text was the target (the decoder’s job). Similarly, we could have used the same architecture to input the text/document into the encoder, and ask the decoder to output the summary. But, I guess, the course creators for this (next, C4W2) week wanted to introduce the decoder-only architecture (like in the GPT) and the way to implement the summarization with it.
In the C4W2 Assignment the special token is used to separate the text from the summary. And also the mask is used to not penalize the model for not getting the text part correct or wrong, so only the summary part is important. As I mentioned, this is decoder-only model.
In the C4W3 Assignment we implement the encoder-only model (actually, one part (the Unsupervised denoising part) of the T5 which is actually the encoder-decoder model). So, in the Assignment the model is trained to predict only sentinels. You can find out more about the T5 in the paper or maybe more concretely here.
In C4W3 we only implemented the encoder part of the model. However the assignment appears to be truncated, i.e. there is not actual model training and prediction, so it was not clear whether we wrote the entire model with encoder, or only a partial model. Since it was said that “bert” is bi-directional, how do we tell from the structure of the encoder? Is it in that the attention wasn’t masked, so the model can see both before and after the sentinels?
That is true. We did not implement the whole T5 model but only the part of it. But the part that was implemented could be the whole model for some application.
Correct (just a mall detail - in BERT case, these are “masked tokens” instead of “sentinels”), when predicting the masked token, the model “can see” all the words before and after, thus bi-directional.