Andrew Ng states that for logistic regularization, the L1 regularization is sometimes thought to increase sparseness more than L2 regularization, with some of the weights becoming zero. But I can’t think of any justification for thinking that. It seems that either one would be equally likely to make some weights become zero.
Is there a way to justify this idea, that L1 producing more sparseness than L2?
I’m sure you can google up a more complete explanation, but here are some thoughts:
L1 regularization uses the sum of the absolute values of weights, whereas L2 uses the squares of the weights, of course. These are being added as effectively “penalty terms” to the cost function to try to decrease the general magnitude of the weights in the hopes that will reduce the overfitting. So L1 punishes small weights exactly to the same degree it punishes large values, whereas the quadratic penalty is more sophisticated: it punishes small values more lightly, but punishes large values much more severely. E.g. if a w value is 0.1, then the L1 penalty is 0.1, but the L2 penalty is 0.01. And if w is 0.01, then L1 is 0.01 and L2 is 0.0001. So the closer the weight is to zero, the less the regularization “forcing function” works to further reduce the weight values in the L2 case.
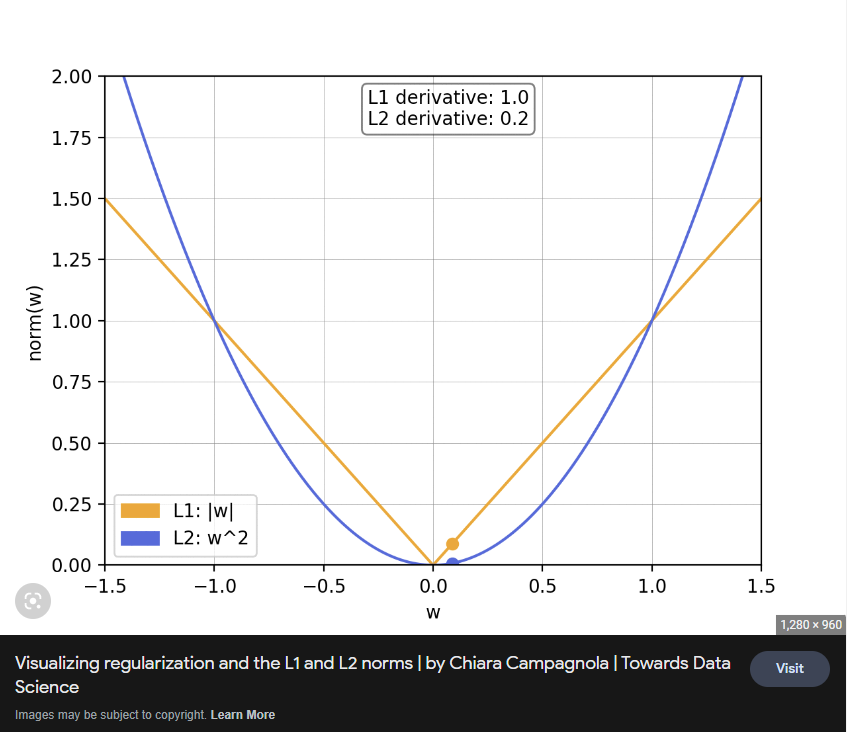
Just to supplement Paul’s answer, here is a graph for a L1 and L2 regularization term. At close to zero, the gradient (slope) in L2 can be much smaller than L1.
Thanks for the illuminating comments. I also found something in the recent 3rd edition of Hands-On Machine Learning, which has a discussion of exactly this as “Lasso Regression” (Least Absolute Shrinkage and Selection Operator Regression), on p 159 and 160, with some figures. The answer is fairly obvious in retrospect, and maybe just what you were telling me: the L1 regression term uniformly reduces each weight by a constant amount each step, so the smallest weights will hit zero early on, and then be kept there.