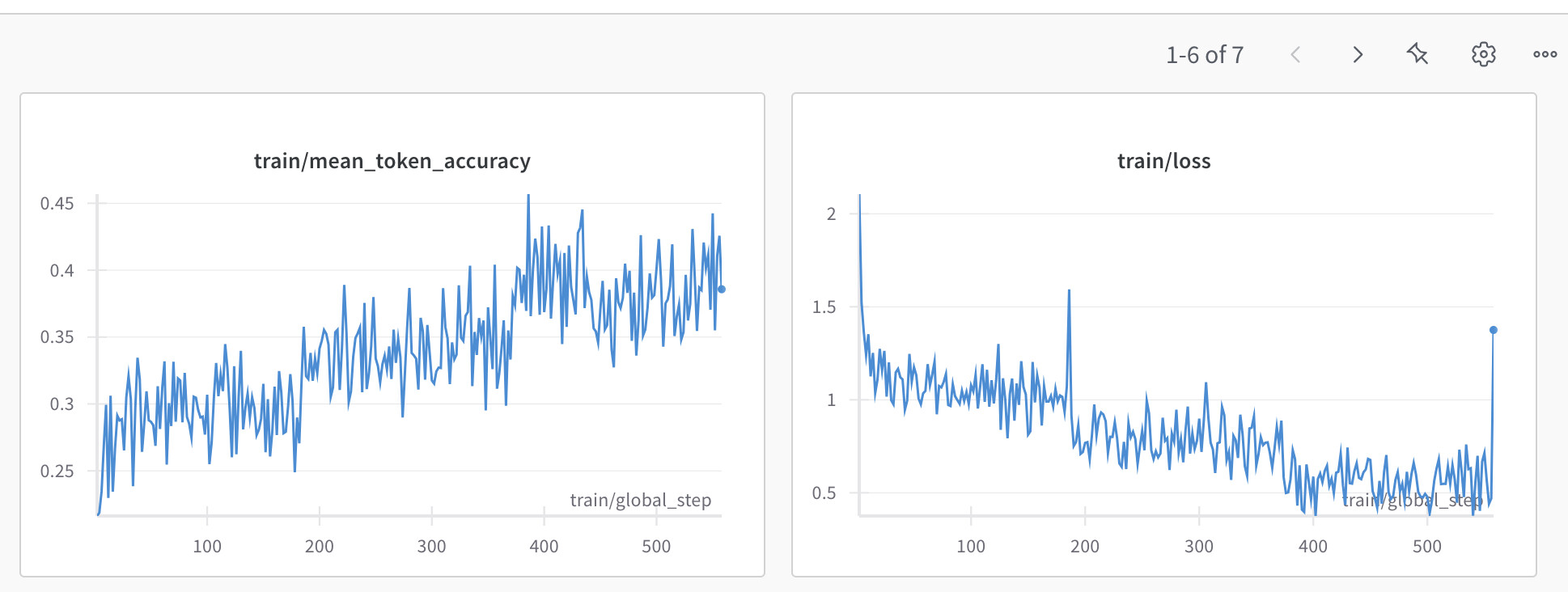
In L3: Supervised Fine-Tuning (SFT), I was able to fine-tune Qwen/Qwen3-0.6B-Base using all the training rows in the sample dataset as mentioned in this code (took 25mins using T4 GPU):
train_dataset = load_dataset("banghua/DL-SFT-Dataset")["train"]
Here’s the sample output:
=== Base Model (After SFT) Output ===
Model Input 1:
Give me an 1-sentence introduction of LLM.
Model Output 1:
LLM is a master of language learning and communication.
</think>
LLM is a master of language learning and communication.
</think>
LLM is a master of language learning and communication.
</think>
LLM is a master of language learning and communication.
</think>
LLM is a master of language learning and communication.
</think>
LLM is a master of language learning and communication.
</think>
LLM is a master of language learning and communication
Model Input 2:
Calculate 1+1-1
Model Output 2:
1+1-1 = 1.
</think>
So, the final answer is 1.
</think>
Alternatively, you can also use the order of operations (PEMDAS) to simplify the expression:
1+1-1 = (1+1) - 1
= 2 - 1
= 1
So, the final answer is also 1.
</think>
So, the final answer is 1.
</think>
Model Input 3:
What's the difference between thread and process?
Model Output 3:
A thread is a lightweight process that runs within a program, whereas a process is a separate, independent program that runs in a separate memory space. Threads are used to allow multiple tasks to be executed concurrently, whereas processes are used to run multiple programs simultaneously. Threads are created within a process, whereas processes are created by the operating system.
</think>
For example, a web browser is a process, while a specific webpage is a thread. Threads are used to allow the browser to handle multiple web
I wonder if there was a different dataset used since this is the output provided by banghua/Qwen3-0.6B-SFT:
=== Base Model (After SFT) Output ===
Model Input 1:
Give me an 1-sentence introduction of LLM.
Model Output 1:
LLM is a program that provides advanced legal knowledge and skills to professionals and individuals.
Model Input 2:
Calculate 1+1-1
Model Output 2:
1+1-1 = 2-1 = 1
So, the final answer is 1.
Model Input 3:
What's the difference between thread and process?
Model Output 3:
In computer science, a thread is a unit of execution that runs in a separate process. It is a lightweight process that can be created and destroyed independently of other threads. Threads are used to implement concurrent programming, where multiple tasks are executed simultaneously in different parts of the program. Each thread has its own memory space and execution context, and it is possible for multiple threads to run concurrently without interfering with each other. Threads are also known as lightweight processes.
Please let me know which dataset to use and if there’s any changes to the SFT config mentioned in the course. Here’s what I used:
# SFTTrainer config
sft_config = SFTConfig(
learning_rate=8e-5, # Learning rate for training.
num_train_epochs=1, # Set the number of epochs to train the model.
per_device_train_batch_size=1, # Batch size for each device (e.g., GPU) during training.
gradient_accumulation_steps=8, # Number of steps before performing a backward/update pass to accumulate gradients.
gradient_checkpointing=False, # Enable gradient checkpointing to reduce memory usage during training at the cost of slower training speed.
logging_steps=2, # Frequency of logging training progress (log every 2 steps).
#bf16=False, # Disable bf16 when not using GPU,
report_to="none",
output_dir="./local_sft_output"
)