I am trying to implement a DNN separately by following optimization Algorithms discussed in Improving DNN week 2. This didn’t happen before implementing mini batch and Adam algo.
I checked my code but can’t figure out the cause. Sometimes it gives me overflow encountered in exp error too.
This warning is occurring in multiple forms as shown by the images and sometimes it doesn’t occur at all and runs just fine.

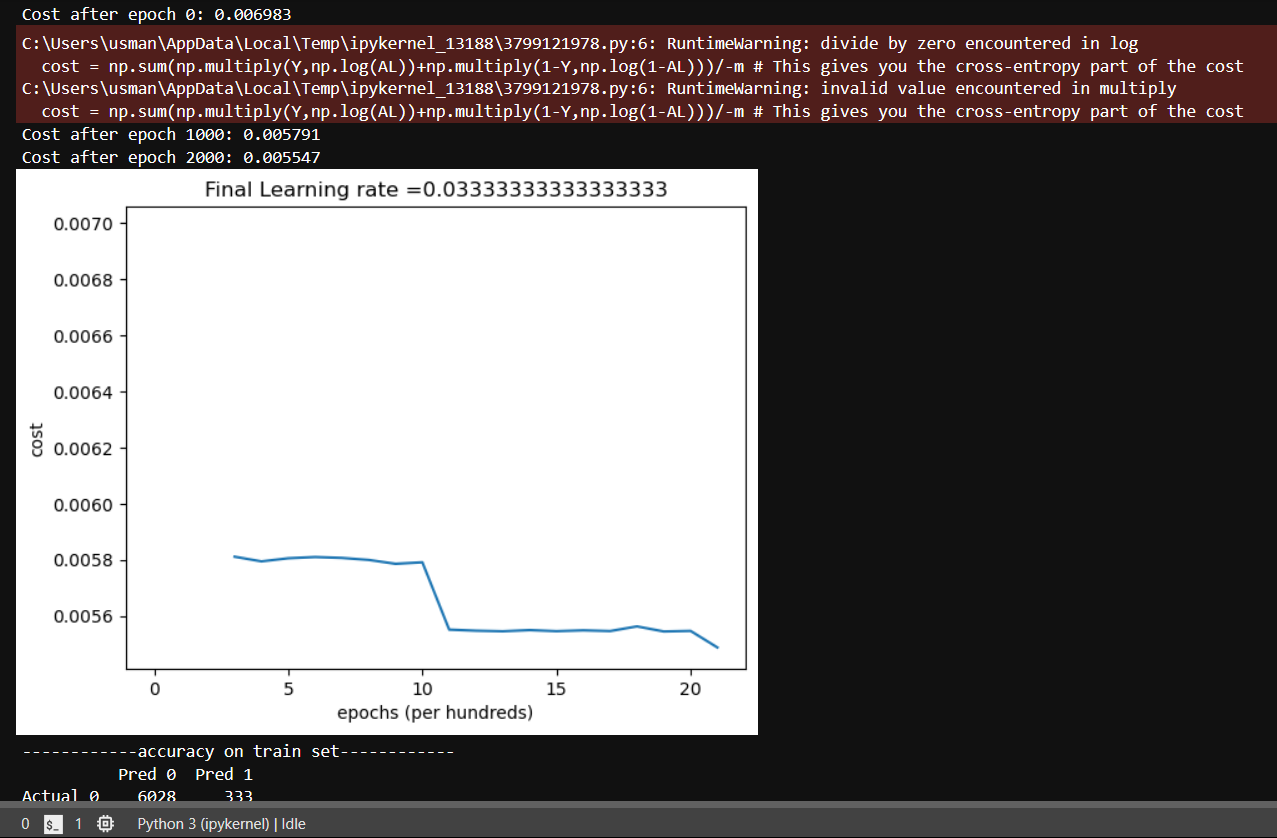
A few thoughts:
- Have your normalized the data set?
- The “divide by zero” might mean that ‘m’ is zero in those mini-batches.-
- Are you using sigmoid() when you compute AL?
- Yes, I am normalizing the dataset.
- Wouldn’t zero encountered in log mean its computing log(0)?
- Yes, I am using sigmoid for the last layer.
Thank you for helping!
Yes, it would.
Typically log(0) should not happen if AL comes from using sigmoid() and you have normalized features.
Due to the randomness of the occurrence, I think it has to do with the random initialization of the parameters or the mini batches generator.
I assume this did not happen when you solved the exercises in this assignment. Note that (as typical here) they set the random seeds, so that the results are actually reproducible.
But since you are solving a different problem of your own, note that NaN can occur because of getting log(0) when you compute the cost in the case that sigmoid “saturates”: mathematically the output of sigmoid can never be exactly 0 or 1, but that’s if you’re doing “pure math” and using \mathbb{R}. But we don’t have that luxury: we have to do everything in the finite representation of either 32 or 64 bit floating point. In float64, I think sigmoid saturates for z > 35 or so.
There are several things to say here:
For starters, just getting NaN for the cost doesn’t really do any harm. The actual J value is not really used for anything. All we really care about are the gradients and those are fine. Well, they will be exactly 0 for the samples with z > 35, but that’s only a problem if all your z values are > 35.
You can actually implement your loss logic to catch the saturation cases. Here’s a thread which discusses that.
Hello guys,
I found a roundabout clipping the Z values between -35 and +35 thus avoiding log(0) in loss calculation from sigmoid and warning message.
Here you go (in your local ipynb file):
def forward_propagation_with_dropout(
X,
parameters,
keep_prob = 0.5):
.../...
Z3 = np.dot(W3, A2) + b3
Z3 = np.clip(Z3, -35, 35) # add this here
A3 = sigmoid(Z3)
...
But as it has been mentioned that is not mandatory in our case.
Francis
2 Likes