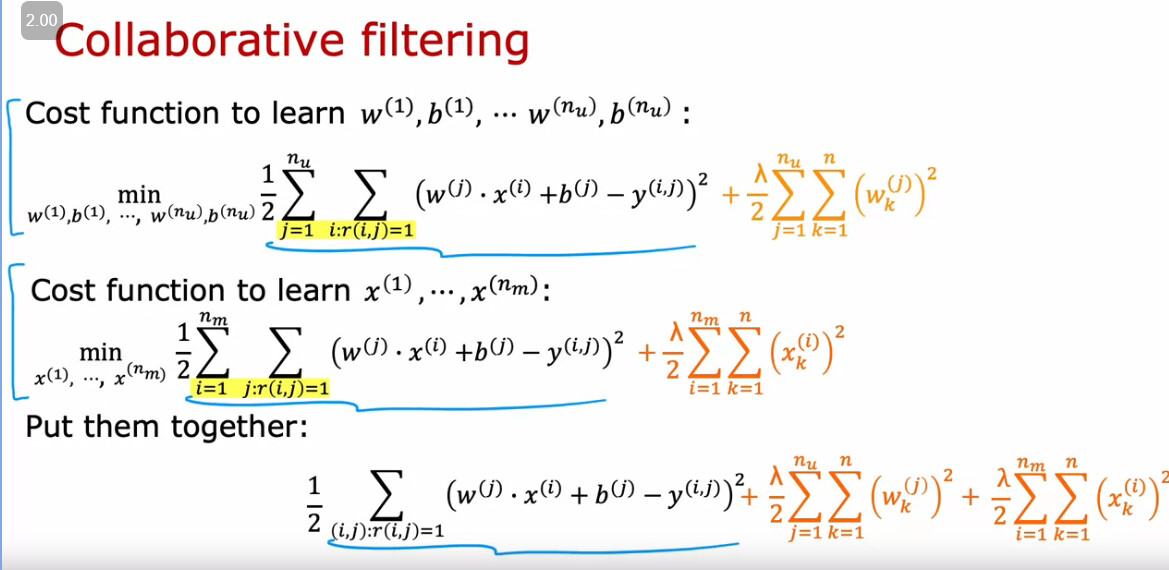
It is said that in order to calculate the Cost function of collaborative filtering, we just add the traditional cost function formula from Linear Regression with the new cost function (for features) and we have the cost function for the whole thing. But in order to calculate the cost function for w and b we need X(i) for all i, and in this case we don’t have those because that’s what we are trying to figure out (unlike previous cases where we had x and we had to figure out w and b ). So if we don’t have all the X(i) values how are we calculating the cost function?
We initialize those w, x, and b into some values so that we can calculate the cost function and the gradients, and from there, we perform gradient descent to change w, x, and b to a set of values better match with y.
Cheers,
Raymond