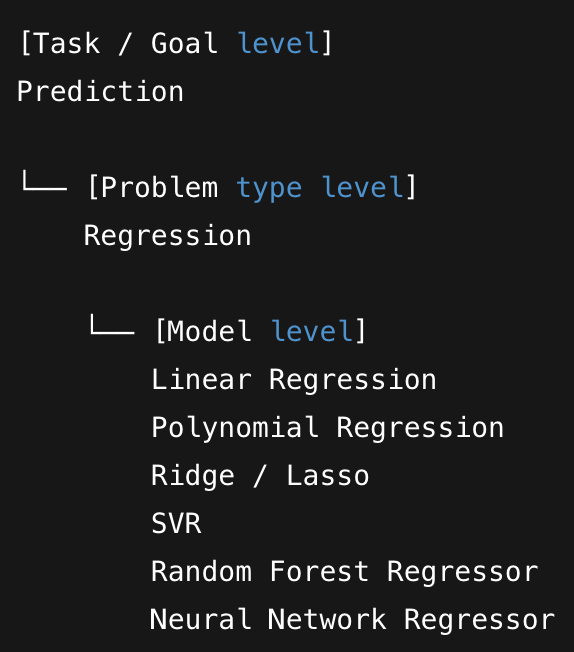
In most ML materials, we usually see the categories: supervised, unsupervised, semi-supervised, self-supervised, and reinforcement learning.
So where exactly does a recommender system fall under this framework?
Should we treat “recommender systems” as another separate category on its own (so it becomes supervised / unsupervised / semi-supervised / self-supervised / reinforcement learning / recommender systems)?
If we classify purely by learning type, is collaborative filtering supervised, unsupervised, or something else?
I’m also confused about how the boundaries between these learning types are defined.
For example, in the anomaly detection lesson:
The training set only has features and no labels → looks like unsupervised learning.
But later in the videos, the validation and test sets do have labels.
So in this case, should the model be considered unsupervised or semi-supervised? Since part of the data (training) has no labels, but another part (validation/testing) does.
Does it actually matter which category of machine learning something belongs to?
In my opinion, if the training process involves labels, that is supervised. In other words, for the anomaly detection algorithm in the lecture, those trainable parameters in the Gaussian were trained unsupervised-wise. As long as those parameters are not changed in the validation/testing phases, I think those phases don’t matter as to what kind of learning those parameters are under.
You might tune the epsilon value (threshold below which a sample is considered abnormal) in the validation stage using the labels, but is that tuning process machine learning at all? Looks like a human tuning to me. If it’s not machine learning, do we need to say it is supervised or not?
Following my idea above, as for whether a recommender system would be considered by me supervised or unsupervised, it depends on the actual training process. If you frame the collaborative filtering problem like the assignment does which is a neural network that takes the inputs user ID and item ID and produces output which is rating, then training such network with the ratings looks like a supervised learning to me. If you frame it as a matrix decomposition problem then I will call it unsupervised.
I would not say that because the ratings are considered labels in the neural network setting, they will be considered labels in any other settings.
When I come across a machine learning problem, I won’t think about which category it belongs to, so I think it’s not important. However, mastering different types of techniques is important to flexibly apply the skills in a new problem. So, I won’t recite which work is supervised/unsupervised/…, only to think about if I can do the work supervised-wise/unsupervised-wise/…
Anomaly detection does use a labeled training set - it’s just very small compared to other supervised methods.
It starts with a large set of unlabeled data, so the statistics can be determined.
Then it uses a small labeled set in order to adjust some anomaly detection threshold based on those statistics.
So I’d agree it isn’t just a pure unsupervised method.
== = = =
I agree that it really doesn’t matter how you group the machine learning methods. You just need to know what methods exist, and what situations they are intended to model - and what situations a particular model is not well-suited for.
For example, you’re not going to use a deep fully-connected neural network for a situation where the sequential order of the examples is important.
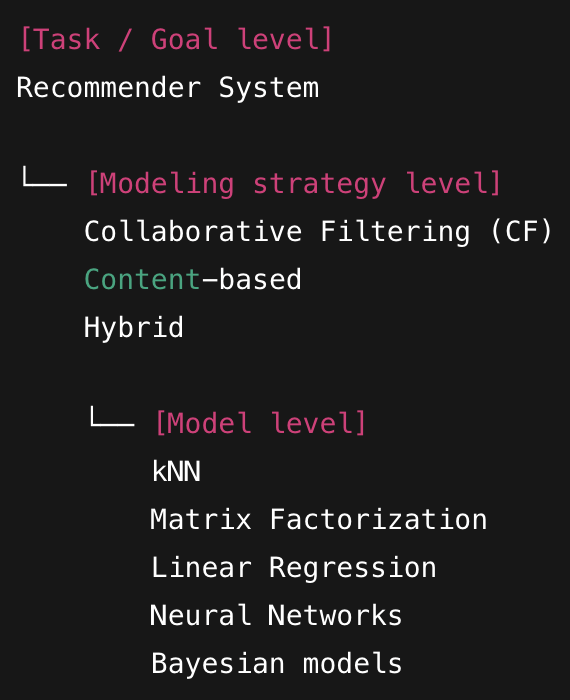
I am not very familiar with the conceptual structure in this area, so I asked an AI for clarification. However, I am not sure whether this understanding is correct.
Collaborative Filtering (CF) can be supervised or unsupervised, whereas linear regression is strictly supervised. Is this difference because they belong to different levels in the conceptual hierarchy?
<picture below, is generated by AI based on my throught>
I don’t have a conceptual structure about it, and I don’t need one to differentiate if it is supervised or not. If you use label in the training process, it is supervised.
CF can be either supervised or unsupervised because you can frame it differently:
As for your conceptual structure, one useful part is that it points out that “Linear Regression” and “Collaborative Filtering” may not fall into the same category. Linear Regression is a method for modeling data, whereas CF is a process that may be achieved by training a Regression model (e.g. the assignment).
I suggest you to google or ask chatbot about “Filtering in mathematical modeling”. The term “filtering” is widely used, and for example, I think I first read about it when I self-studied Kalman Filtering for signal processing many years ago.
So, when I am trying to understand a new machine learning method, can I categorize it as one of the following:
methods with a clearly defined model structure (e.g., linear regression)
methods with a clearly defined algorithm (e.g., k-means)
methods with a clearly defined process or paradigm (e.g., collaborative filtering)
and possibly other categories that I have not learned yet
Or is this way of thinking unnecessary? If it is unnecessary, then when I encounter an unfamiliar problem, how should I identify and understand a new method?
I won’t comment on whether that thinking is necessary or not, because everyone has their own way to learn and apply skills. For example, I wouldn’t focus on conceptual structure to tell whether a training process is supervised or not. That’s one difference between us.
If I write a book, I probably need to give these structural or systematic approaches more thoughts, but now I want to see how well a method works on my problem.
For me, when there is an unfamiliar problem, I will google or prompt a chatbot for ideas. When a method (new or not) comes up, I will read about it, experiment with it, grow my experience on it, and see how well it performs.
I understand, thank you very much !!
I sincerely appreciate your patience in answering my confusion . Through discussing and asking you questions, I’ve known that there is still much more for me to learn…
I encourage you to look into each new method individually and, for now, not rely too much on the categorization framework.
Take your categorization above as an example, I guess you differentiated Linear regression and K-means because you had known very well that for Linear regression, you needed to have a linear equation in prior and that equation is the model structure, whereas for K-means it does not have such equation but it’s the algorithm that achieves the clustering. If I understood correctly, these distinction came out from your very good understanding of those approaches - this means your understanding of each method helps you spot critical differences / common properties among the methods.
If I were you, as I get to know more methods, my categorization framework may be updated. Given that the framework was still in progress, when a new method shows up, I would still try to see which category (or categories) it falls under to see how good my framework is, but after that I would always study it with a refreshed mind (as if it is unrelated with any other algorithm). I would still care more about how it performs on my data, as I said, but because this is the “if I were you” case, I would also prioritize the updating of the framework given any new knowledge I have acquired throughout my process of “read about it, experiment with it, grow my experience on it, and see how well it performs”. At the end, I would achieve both - hands-on experience and an updated framework.
Having said that I would learn it with a refreshed mind, I also admit that, sometimes, my prior knowledge about one method helps me understand another method. However, there is no guarantee that it always be like that and also we couldn’t predict in what way is prior knowledge going to help. In other words, I wouldn’t rely too much on it, or when I get to learn a new method, it wouldn’t be my first step to look for similarity with methods I have already learned. I would just let the similarity to pop up in my mind naturally as I study it.
I do think your categorization framework is interesting and can be very useful, only that’s not my focus now. Apart from this difference, I do see something in common which is to achieve some in-depth understanding of method like what you have shown in your last categorization framework. Given this, I believe you will come up with a useful framework midway of your learning journey.
Yes, you are absolutely 100% right. My current way of distinguishing between linear regression and K-means is indeed based on what I have learned so far and my current level of understanding.
Thank you very much for sharing your valuable experience and insights., and I will definitely take your advice while keeping an open mind and continuously updating my own learning framework.