Hi~
I don’t understand a lot of things, so if you know anything, please let me know.
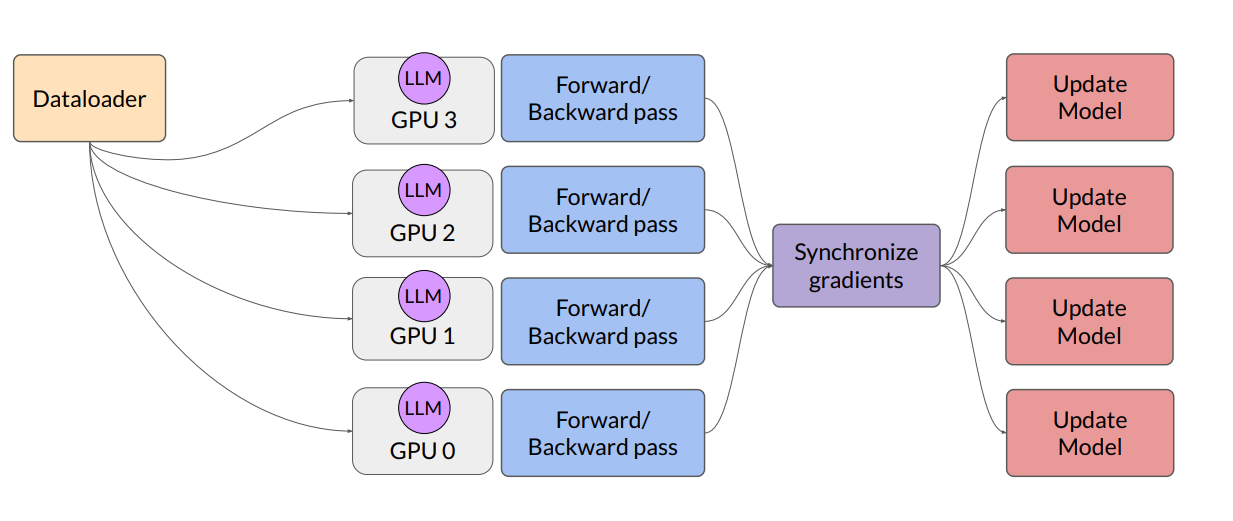
Q1) In Distributed Data Parallel, how do gradients of model on each GPU be synchronize?
calculatating mean of each gradients updated? I want to know the way of synchronizing gradients.
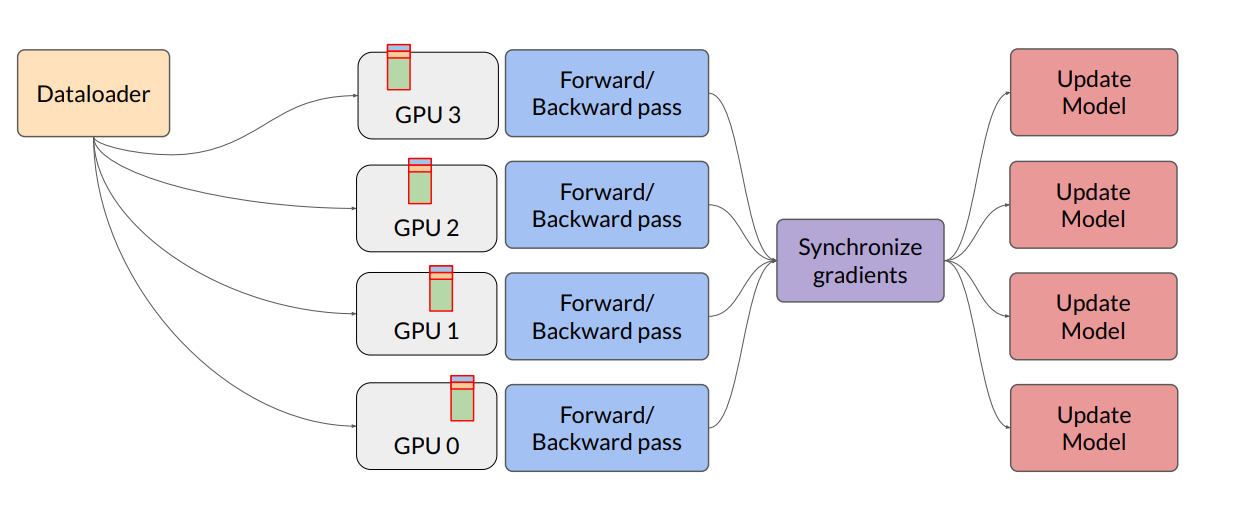
Q2) In Fully Sharded Data Parallel, what does getting weights mean?
I understand that why getting weights is to execute an operation but forward pass is processed after getting weights. how is the operation executed after getting weights different from forward pass or backward pass?
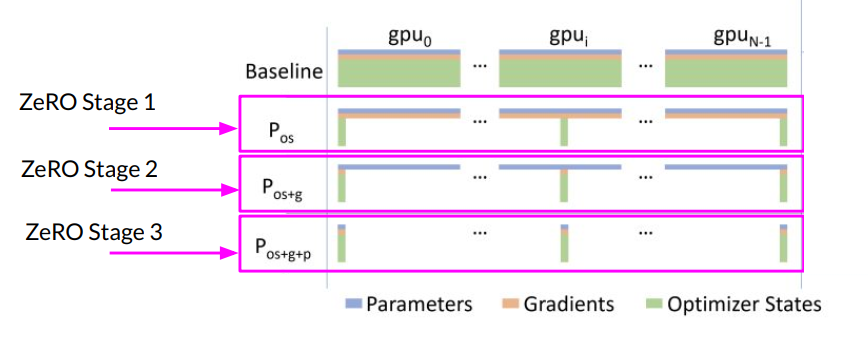
Q3) Is ZeRO stage each step of the whole process, or is it a choice for users to use any of the three?
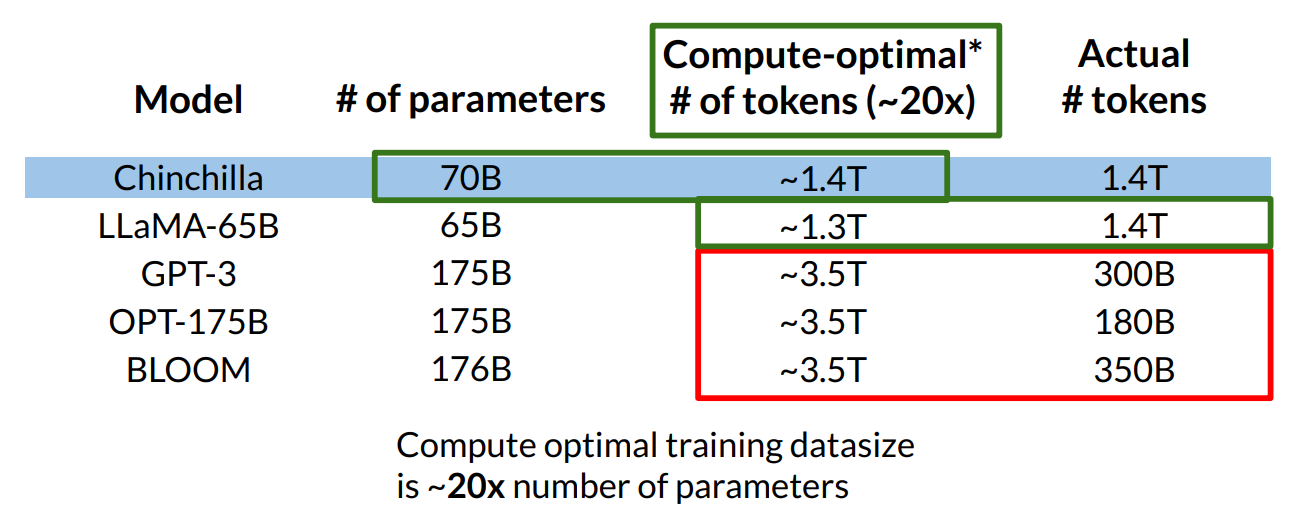
Q4) does the number of token literally mean total tokens in model’s vocabulary?