Hi,
I tried implementing the programming exercise [Logistic Regression as a Neural Network] using pytorch and found that:
Final Train Accuracy : 34%
Final Test Accuracy : 66%
However, in the exercise it comes out to be :
train accuracy: 99.04306220095694%
test accuracy: 70.0 %
Is this difference expected or something is wrong with my implementation?
That probably means that you “flattened” the data incorrectly for the way that PyTorch assumes it is oriented. Or that you “scrambled” the data in the flattening process. Here’s a thread about that.
Here’s a thread which also talks about the number of true and false values in the train and test data. Your numbers show that your model is just producing “yes” for all samples.
So, yes, this indicates a problem in your implementation.
I flatten the input as mentioned in your first thread:
// Flatten X for train and test
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1) # (batch_size, dim)
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1) # (batch_size, dim)
// Reshape from (batch_size, dim) to (dim, batch_size).
train_set_x_flatten = train_set_x_flatten.T
test_set_x_flatten = test_set_x_flatten.T
So, the dimensions are
The dimensions X of the train set (12288, 209)
The dimensions Y of the train set (1, 209)
The dimensions X of the test set (12288, 50)
The dimensions Y of the test set (1, 50)
My model has 1 neuron which takes as input (12288, 1) and passes to a sigmoid.
Then I get the error :
RuntimeError: mat1 and mat2 shapes cannot be multiplied (12288x209 and 12288x1)
When we implemented Logistic Regression directly in python, the math formulas are:
Z = w^T \cdot X + b
A = sigmoid(Z)
In that formula we have w with dimensions 12288 x 1 and X with dimensions 12288 x 209. So the result of that should have dimension 1 x 209.
So how did you express that computation in PyTorch? It seems like that’s where the problem is. Maybe PyTorch assumes that the “samples” dimension is first when you declare a “dense” layer.
Here is the model:
class NN(nn.Module):
def __init__(self):
super(NN, self).__init__()
self.fc1 = nn.Linear(12288, 1, bias=1)
def forward(self, x):
x = self.fc1(x)
x = F.sigmoid(x)
return x
Here is the documentation for PyTorch nn.linear. Note that it says that the input should be of dimension samples x features.
So now our dimensions are:
The dimensions X of the train set (209, 12288) # samples x features
The dimensions Y of the train set (209, 1)
The dimensions X of the test set (50, 12288)
The dimensions Y of the test set (50, 1)
And we get
Final Train Accuracy : 34%
Final Test Accuracy : 66%, does this mean we have to rebalance the dataset as you mention in the second thread ?
Just wondering why numpy and this implementation produces different results on the same dataset ?
What does your training look like? You’ve shown the model, but not how you do the torch equivalent of “compile()” and “fit()” in “TF world”.
import numpy as np
import copy
import matplotlib.pyplot as plt
import h5py
import scipy
from PIL import Image
from scipy import ndimage
from lr_utils import load_dataset
from public_tests import *
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
num_epochs = 5000
# Loading the data (cat/non-cat)
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
# Flatten X for train and test
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1) # pytorch uses (batch_size, dim)
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1) # pytorch uses (batch_size, dim)
# Reshape from (batch_size, dim) to (dim, batch_size). Note Y is already in this format so we don't convert
# train_set_x_flatten = train_set_x_flatten.T
# test_set_x_flatten = test_set_x_flatten.T
# Understand the shape of dataset
print(f"The dimensions X of the train set {train_set_x_flatten.shape}")
print(f"The dimensions Y of the train set {train_set_y.shape}")
print(f"The dimensions X of the test set {test_set_x_flatten.shape}")
print(f"The dimensions Y of the test set {test_set_y.shape}")
# Standardize dataset
train_set_x = train_set_x_flatten / 255.
test_set_x = test_set_x_flatten / 255.
class NN(nn.Module):
def __init__(self, input_size):
super(NN, self).__init__()
self.fc1 = nn.Linear(input_size, 1, bias=1)
def forward(self, x):
x = self.fc1(x)
x = F.sigmoid(x)
return x
# set device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# Initialize network
model = NN(input_size = train_set_x.shape[1]).to(device)
# Check final shape
test = np.random.randn(train_set_x.shape[0], train_set_x.shape[1]) # (batch_size, dim)
test = torch.tensor(test, dtype=torch.float32).to(device)
assert test.dtype == torch.float32, "Linear layer is float32, convert input to float32 as well"
result = model(test)
np_result = result.detach().cpu().numpy()
print(np_result.shape) # (num_classes, 1) (209, 1)
assert np_result.shape[0] == train_set_y.shape[0] and np_result.shape[1] == train_set_y.shape[1], "Output dimensions are not correct"
# Hyper-parameters
learning_rate = 0.001
# Setting up options
criterion = torch.nn.BCELoss() # Binary Cross Entrophy Loss
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Running test
def check_accuracy(X, Y):
with torch.no_grad():
X = torch.tensor(X, dtype=torch.float32).to(device)
Y = torch.tensor(Y, dtype=torch.float32).to(device)
Y_pred = model(X)
accuracy = (Y_pred == Y).sum() / X.shape[0]
return accuracy
# Using batch gradient descent, i.e all the data is used per epoch
for epoch in range(num_epochs):
train_set_x = torch.tensor(train_set_x, dtype=torch.float32).to(device)
train_set_y = torch.tensor(train_set_y, dtype=torch.float32).to(device)
prediction = model(train_set_x)
loss = criterion(prediction, train_set_y)
loss.backward()
#gradient descent with adam
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
accuracy_train = check_accuracy(train_set_x, train_set_y)
accuracy_test = check_accuracy(test_set_x, test_set_y)
print(f" Final Train Accuracy : {accuracy_train:.2f}, Final Test Accuracy : {accuracy_test:.2f}")
It is late in my timezone (UTC -7), so I will not be able to come up with a coherent response tonight. I hope to have time to look at this in more detail tomorrow (in maybe 10 hours or so). My plan would be to try to implement this first in TF and see how that works and then try torch. My exposure to torch is from the GANs specialization here from DLAI, but it’s been a while since I’ve actively used torch. So it will take me some time to get familiar with that again.
Great, thank you. Take your time and let me know when you find out !
Ok, today I had time to do the first part of my experiment: it was pretty easy to implement both Logistic Regression and the 4 layer model from DLS C1 W4 A2 in TensorFlow. With just a little bit of work to deal with the fact that TF expects data in the “samples first” orientation, it all just works.
Now I have to take the next step to duplicate this in pytorch. More news tomorrow, I hope.
Regards,
Paul
Hey @paulinpaloalto,
Just curious, was your TF model able to replicate the accuracy on the train and test data ?
I didn’t try to tune it, but I did get numbers very similar to the Week 2 and Week 4 4 layer network:
LR results with TF:
7/7 [==============================] - 0s 2ms/step - loss: 0.2639 - accuracy: 0.9569
Loss = 0.2638537883758545
Train Accuracy = 0.9569377899169922
2/2 [==============================] - 0s 3ms/step - loss: 0.5976 - accuracy: 0.7600
Loss = 0.5975509285926819
Test Accuracy = 0.7599999904632568
4 Layer model results with TF:
7/7 [==============================] - 0s 2ms/step - loss: 0.0022 - accuracy: 1.0000
Loss = 0.0022235156502574682
Train Accuracy = 1.0
2/2 [==============================] - 0s 3ms/step - loss: 1.5103 - accuracy: 0.7200
Loss = 1.5102972984313965
Test Accuracy = 0.7200000286102295
This is just running 150 epochs with Adam optimization and no attempt to tune the epochs or learning rate.
I have not finished my PyTorch implementation, but I’ve gotten far enough that I think the problem with your results is simple: you are just calling the model to generate predictions and then comparing those to the labels. That doesn’t work because the predictions (the direct output of the model) are sigmoid output values, so they are never equal to the labels. You have to round them to 0 or 1, as in:
pred_boolean = (Y_pred > 0.5)
in order to compare to the labels, right? So it’s just that your check_accuracy function is not correctly implemented. Should be an easy fix.  Not sure that’s the whole story yet, but please give that a try and let me know.
Not sure that’s the whole story yet, but please give that a try and let me know.
Hi Paul,
Thank you for looking into this, its been a couple of busy days and I finally got a chance to try out what you recommended.
In the code mentioned here : Implementing using pytorch does not produce same results - #10 by krithika_govindaraj
I changed the check_accuracy function to:
def check_accuracy(X, Y):
with torch.no_grad():
X = torch.tensor(X, dtype=torch.float32).to(device)
Y = torch.tensor(Y, dtype=torch.float32).to(device)
Y_pred = model(X)
Y_pred_bool = Y_pred > 0.5
accuracy = (Y_pred_bool == Y).sum() / X.shape[0]
return accuracy
Still seeing the same numbers.
Final Train Accuracy : 0.66, Final Test Accuracy : 0.34
Also, I printed out Y_pred , its zero all the time. Do you happen to know why this might be happening ?
That’s what you said in the very first post that started this thread. Here’s what you just said in the most recent post:
Those are actually not the same numbers, right? They are reversed from the previous numbers.
But it means you’ve just flipped everything. If you take a look at the number of true and false samples in the datasets, what you find is:
The training dataset has 34% cats and 66% not cats.
The test dataset has 66% cats and 34% not cats.
So it looks like your initial model predicted “cat” always and your most recent model predicts “not cat” always. That should be a good starting point to debug what is going on. What are the actual model predictions before you do the Boolean conversion?
Yes, you are right. My bad, these numbers are flipped.
It’s all 1, so as you said always predicts as cat
This is the code change.
def check_accuracy(X, Y):
with torch.no_grad():
X = torch.tensor(X, dtype=torch.float32).to(device)
Y = torch.tensor(Y, dtype=torch.float32).to(device)
Y_pred = model(X)
print(Y_pred)
Y_pred_bool = Y_pred > 0.5
accuracy = (Y_pred_bool == Y).sum() / X.shape[0]
return accuracy
What does the print out of the actual Y_pred values show?
BTW it looks like I forgot to mention it, but I didn’t have any trouble getting this model to work in pytorch. I haven’t tried any tuning, but it gives results pretty similar to the numpy and the TF variants of this.
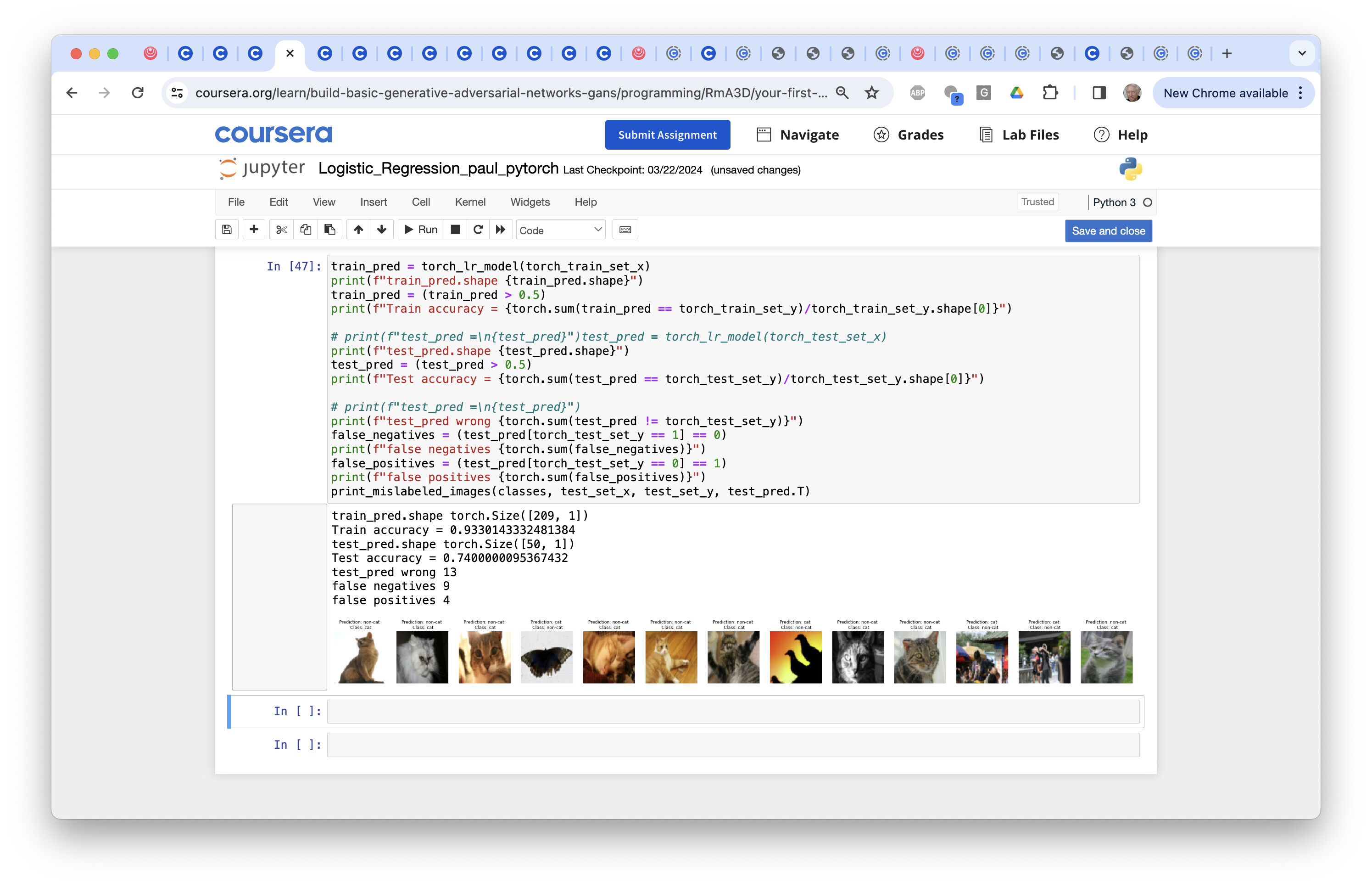
Here are my pytorch results from the Logistic Regression model:
So I get 93% train accuracy and 74% test accuracy without any effort to tune the gradient descent (epochs and learning rate). Pretty comparable to the numpy and TF results.