I noticed in the lecture introducing self-attention the weight matrix multiplied with embedded word vector directly to generate k, q and v while in the lecture for multi-head attention, in order to generate multiple channels to represent the word in the sentence, there is a matrix for each channel to multiply with k,q and v and generate the result Wq, Wk and Wv to feed into the attention function, is that mean there is a additional weight matrix introduced into in the multi-head lecture which is not mentioned in self-attention lecture and weight matrix in that lecture is different from the one for multi-head attention?

Hi @Feihong_YANG ,
Let me see if I understand your question and attempt an answer here:
The multi-head attention is several self-attention models working in parallel.
Each one of these heads, meaning each one of these self-attention modules, is fed with the positionally encoded embeddings resulting from the input. When each self-attention module receives this input, which is usually called the hidden_state, it is transformed into 3 vectors: key, query and value. This transformation is done with a linear layer: one linear transformation for the key, one linear transformation for the query, and another for the value. Each one of these linear transformations are weights that the model will learn in training.
This means that if we have 4 heads in the multi-head attention, we will have 4x3 linear transformations (and equal number of weight matrices to train).
Does this answer your question? Any thoughts?
Hey Juan,
Thanks for the reply and this is exact what my understanding of self-attention and the process would be repeated as many as the number of heads when performing the multi-head attention. But I’m miss leaded by the slice provided in the lecture uploaded here for the multi-head attention. It shows as if for the process x → q,k and v presented with a single arrow and before these vectors performing the attention calculation there are another set of W matrics to multiply with q,k and v respectively, I’m not sure why there is another set of linear transformation introduced here or it’s just a mistake in the slice?
I guess you are referring to the Wk, Wq, Wv … these are the same ones we are referring to.
If we look at it in code, this would be:
q = nn.Linear(embed_dim, nhead )
k = nn.Linear(embed_dim, nhead )
v = nn.Linear(embed_dim, nhead )
Here, embed_dim is the size or dimension of the embeddings. In the original paper, this would be 512, and nhead is the number of heads. Again, in the original paper this is 8.
and then you do this:
attn_outputs = scaled_dot_product_attention(q(hidden_state), k(hidden_state), v(hidden_state))
Here, we are passing the hidden_state, which is basically the positionally encoded embeddings, then each one is linearly reduced, and then used to calculate the scaled dot-product using the known formula (as seen in the paper).
I hope that by seeing this in code this makes more sense now ![]()
Thoughts? Does it solve your question?
Hi @Juan_Olano
Let me know if there is a typo in your comment said “… this would be 512, and head_dim is the number of heads. Again,…”, here did you mean head_dim is the number of dimension of a single head? And the Pytorch function q,k and v here are the linear transformation referred in the lecture self_attention
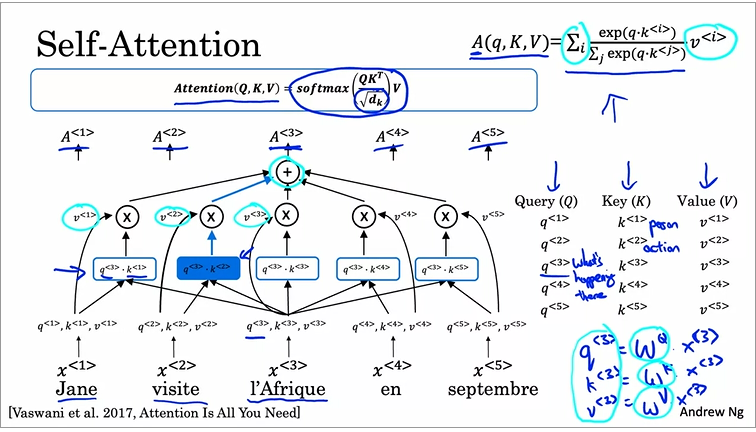
q3 = Wq * x3 for q
k3 = Wk * x3 for k and
v3 = Wv * x3 for v
as shown in my first slice? If so then this would be my understanding of that there is only layer transformation from x (word embedding) to k,q and v and followed by dot product attention operation.
My confusion comes from my second slice which there is a x → q,k and v, after this the generated q,k and v shown in the slice associated with matrix Wi again as shown there and i is denoting specific head, thus it becomes WiqQ, WikK and WivV as input for the follow up dot product attention operation, as you can see on the second slice it present Attention(WiqQ, WikK, WivV), not sure if there is a mistake in the slice.
You are right, I had a typo. Instead of head_dim I meant num of heads, or nhead. I have corrected my post for future references. Thank you for the heads up!!!
I think that in the 2nd slide the notation being used is representing the multiple matrices across heads. If we split this it would be as shown in my code above for each head:
In each head:
q = Wq * x
k = Wk * x
v = Wv * x
Where x is the embeddings matrix (the input to the transformer affected with the positional encoding), and Wq, Wk, Wv the weights of each q, k, v learned, to effect the linear transformation in the ‘x’.
Again, the 3 lines above would be repeated once per head. If there’s only 1 head, then we would have 1 matrix for q, 1 for k and 1 for v. If there are more than 1 heads, then there will be as many matrices as heads we have defined. If nhead = 8 then we would have 8 matrices for each one of the ‘q’, and the same for ‘k’ and ‘v’.
Once we get the q, k, and v, we apply the scaled dot-product attention formula.
Hi @Juan_Olano sure thing!
If it’s
q = Wq * x, k = Wk * x and v = Wv * x
and
If nhead = 8 then we would have 8 matrices for each one of the ‘q’, and the same for ‘k’ and ‘v’.
that’s totally fine. But why in slice 2 it becomes
Wq * q, Wk * k and Wv * v
as input even after q, k and v already transformed from x? If that’s the case isn’t that becomes for each head:
step 1:
q = Wq[1] * x,
k = Wk[1] * x
v = Wv[1] * x
step 2:
Attention(Wq[2] * q, Wk[2] * k, Wv[2] * v)
and we have 2 times transformation before feeding into the dot product attention function?
That’s why I think the second slice confusion.
May be the 2nd slice may lead to this confusion. The truth is there is only one linear transformation:
The embeddings enters the attention module and there is one linear transformation to come up with qkv. The linear transformation turns each embedding from a model_dimension to a model_dimension//nheads. If the model dimension is 512 and the heads is 4 then it turn each embedding into qkv of dimension 128. And after that follows the famous scaled dot-product formula.
I see, and the concatenated heads generated multiply with Wo the result still be 512 even before the Add & Norm layer right?
Exactly! When the output of the heads is concatenated, we get back to the original model dim, in this example 512. I think you got it perfectly!
1 Like