Hi,
I am confused about the relation between these two examples. Shouldn’t they both have the same dimensions given that the second comes from the same data-set as the first one? Shouldn’t all m examples have the same shape of (n,n,c)?
Hey @Moutasem_Akkad,
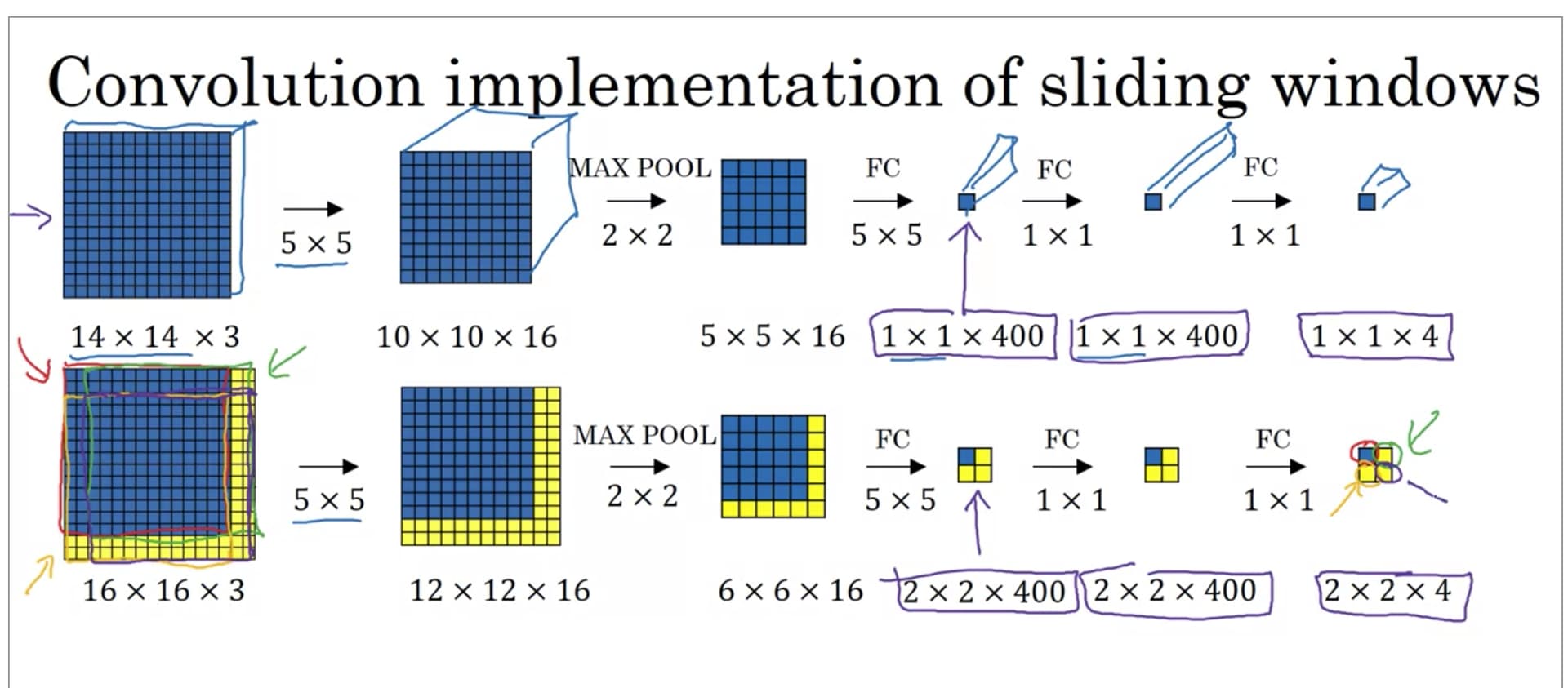
At 5:19, Prof Andrew explicitly states that
" So let’s say that your convnet inputs 14 by 14 images or 14 by 14 by 3 images and your tested image is 16 by 16 by 3."
In simple words, the second image is from the test set, and the first image is from the training set. This has been included with the purpose to demonstrate that how despite of having a different sized image in the test set, the Original Sliding Windows still works in the same way. I hope this helps.
Regards,
Elemento
Yes, wouldn’t the test and training would be the same given that you will start with m training examples and then split them into training and testing?
It is completely possible for a single dataset to consists of differently sized images. In fact, a dataset curated with the help of real-world examples, will most certainly contains examples of different sizes, and depending on the pre-processing involved, the examples may be brought to a realm of uniform size and in certain cases, they may not.
Another scenario could be that the training set consists of uniformly sized examples for an easy modelling, but the test and cross-validation sets consists of differently sized examples to more accurately represent the real-world data that the model might get to see during its production lifetime.
But keeping that fact aside, the primary motive behind including this example is to demonstrate how the convolutional implementation of sliding windows algorithm decreases the computation required to calculate the output. In other words, irrespective of the size of the input image, the Sliding Windows algorithm will still work, that too with reduced computational requirements. I hope this helps.
Regards,
Elemento