Question 1
The lecture title is “Relationship between MAP, MLE and Regularization” but the lecture only shows how regularization and maximum likelihood actually match. MAP is missing.
Question 2
At time 2:12 / 5:50, What is maximum likelihood with bayes? I thought that bayes is only related to MAP? Why maximum likelihood with bayes is equal to P(Data | Model) * P(Model) ?
Question 3
May i know which theory is this statement taken from?
At time 3:10 / 5:50 of the lecture,
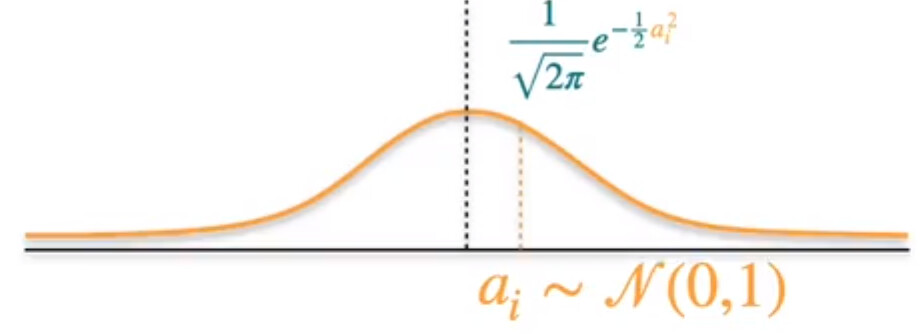
Model 1 has an equation ax +b,
the coefficient a is selected from the standard normal distribution,
I am going to give you some idea, but for the answers of your posted (and any follow-up) questions, it may require you to go thru the video a couple more times and/or reach out to the internet for other reference.
So below is the full picture for the connections between bayes and all other terms.
Essentially, the regularization effect comes from the prior.
I recommend you to try to come up with your own answers to your posted and any new questions (and links to any of your reference are welcome), and we can discuss your answers
Cheers,
Raymond
PS: I googled the title of this thread and some relevant results showed up!
Sure, @JJaassoonn. Please take your time, and in your next reply, along with any questions that’re still not solved, please try to share your answers too, because then, we can discuss based on your answers.
It is, afterall, your business to figure out answers that are convincing to you.
It is not any well-known theory. It is an assumption. What they are doing there is to establish an assumption that speaks, given the form of equation fixed at a x +b , what is the probability that the model takes a certain value of a.
You may want to google with keywords like “bayesian” “regression” “model assumption” and find some relevant reads. If “why Gaussian” puzzles you, you may add it to the list of the keywords, along with any other keywords that are puzzling.
You see - most of the above keywords appeared in the lecture, so you can come up with more yourself to steer your search. Search takes time and effort to find, distill, organize and verify information, but it will pay off. Look forward to your findings!