Hi @ developer of this course
Video Title and Ungraded Lab Title: Building a Simple Text Classifier in PyTorch
I was going through the video and lab explanation of simple text classifier explaining embeddingbag and manual pooling techniques to classify distinctive fruit or vegetable classes.
But I just wanted to add that these both techniques would fail when it would come to create a text classifier for synonyms or opposite words as the model works more on words of embedding based on mean, max and sum.
I understood you probably wanted to explain the two concepts here, but mentioning these two techniques limitation would also would have added to content quality of the course.
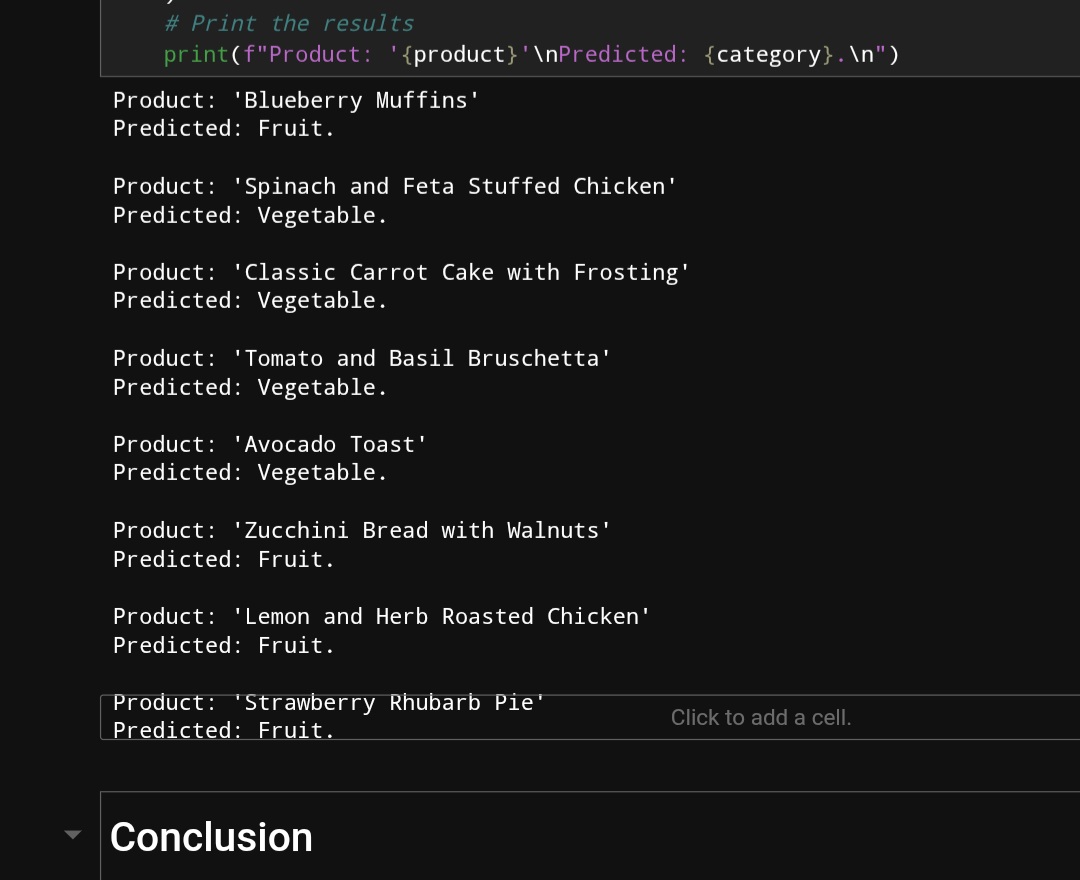
Like for the product was labelled as fruit for lemon which is correct but the recipe description mentions it as **Lemon and Herd Roasted Chicken" as a fruit recipe in a poor labelling when it comes to realistic contextual understanding of this recipe as lemon is a flavor and the main ingredient is the chicken, so this actually wouldn’t come under neither fruit-recipe not vegetable recipe, rather a distant recipe category of Mixed recipe.![]()
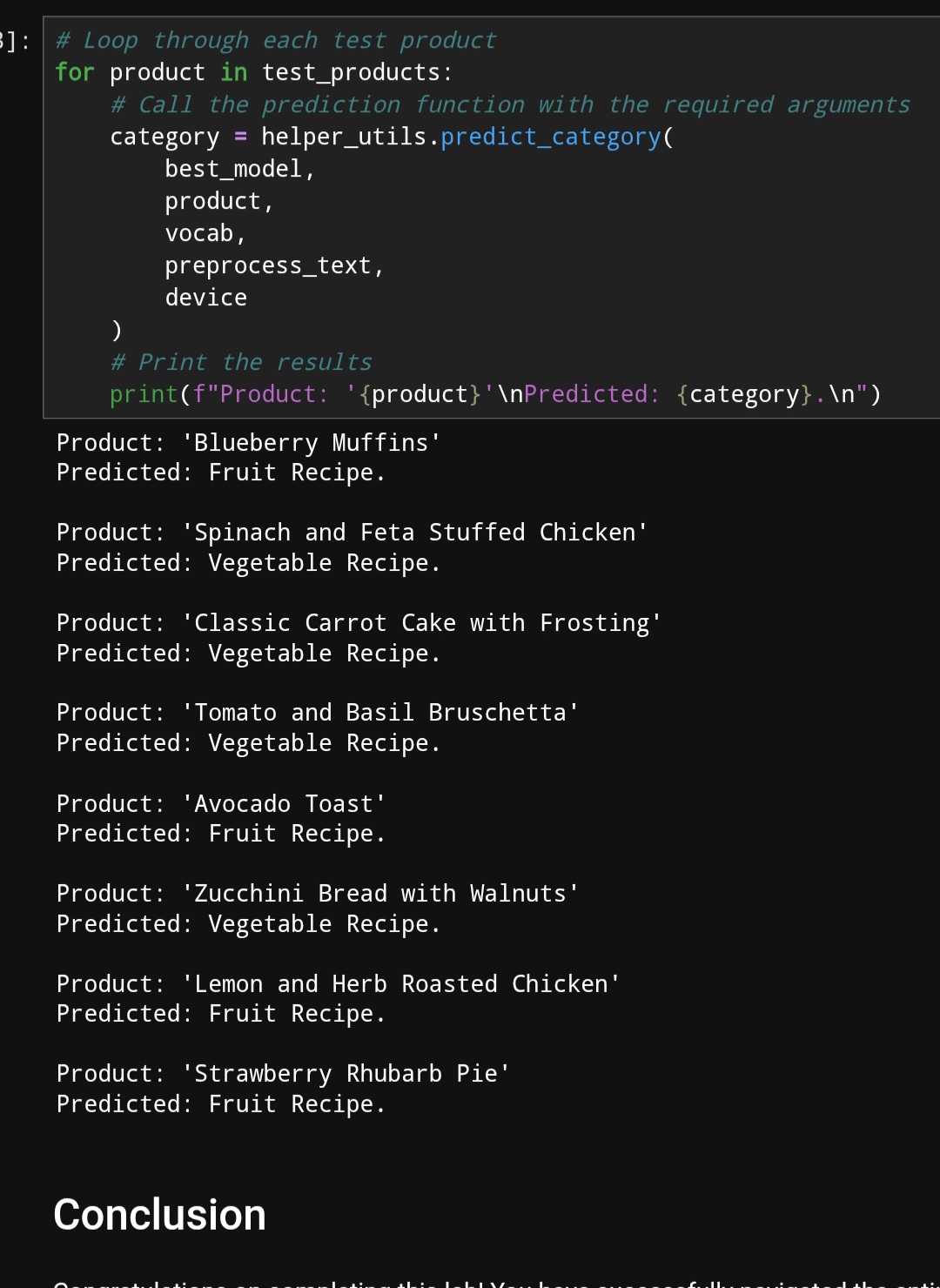
So model is clearly just working based on encoded labels instead of embeddingbag pooling or manual pooling..
Even Ungraded Lab: Fine Tuning Pre-Trained Text Classifier has the same labelling issue where avacado Toast is labelled as Vegetable here where as Avacado is considered and labelled as fruit in the Embeddingbag pooling and manual pooling text classifier (please compare the two images),![]()