Hello,
So I wanted to code the linear regression algorithm by myself from scratch. I did that. I got to a situation after a lot of debugging and error-correction. I got a linear fit curve for one feature and one output dataset. The straight line seems very well fitted. But then I thought I can’t be sure so I tried to implement scikit linear regression library/module. And I plotted those results as well. Now for me who has just started last week in machine learning and linear regression I thought the answers must be same, at least very close to each other. But what I got confused me. I got w and b as 9.44996 and 24.8482 respectively and using scikit I got 10.45667 and 17.5454 respectively. Now these values are not close. I followed everything and I checked everything like I found out the gradient dj_dw and compared it with numerical gradient through following code-
eps=1e-4
w_eps=w+eps
cost_p=self.model_cost(w_eps,b)
cost_m=self.model_cost(w-eps,b)
grad=(cost_p-cost_m)/(2*eps)
eps is epsilon, a very small quantity and then I am calculating gradient. These two gradients were very very close, differed in 4th decimal place. Then I plotted learning curve (loss vs iteration) The loss fell pretty fast. Then I compared the mean squared error, I found this using scikit for both the implementation. Now here is something very confusing- My implementation got mse as 31.2709 and scikit’s implementation got 42.5947. So what mine has less error? but my curve is not as well fitted as compared to scikit’s one. What am I missing here? Clearly I can’t be better than a library if nothing both of them should be very close.
Note- I have removed regularization from scikit’s sgd and also I have used same learning rate and ran the two codes for same number of iterations. I can upload photos of the curve if anybody wants that. I am only allowed single photo so I am uploading curve fit of my implementation.
Please if anybody can tell me what’s happening? Is there something different with scikit or what?

That’s just an approximation of the gradients.
Real gradient descent uses equations based on taking the partial derivative of the cost equation.
I have actually used the real gradient formula only in my implementation. The code snippet I wrote is just a numerical way of calculation and I did that to check whether my code implementation of gradient is working or not.
Here are a couple of other thoughts:
It’s very difficult to judge when a regression has converged just by eyeballing the cost history. Depending on the magnitude of the features, you may have to limit the vertical scale of the plot in order to get a good assessment.
Did both your methods use the same optimization method? Your hand-written code probably used fixed-rate gradient descent for a fixed number of iterations. Did your solution using scikit-learn use the same method?
In your solution, what stopping criteria did you use?
I see you used sgd with sckit-learn: That’s stochastic gradient descent. It will give a different result than the fixed rate batch gradient descent that I believe you implemented.
SGD may also include other optimizers, such as Adam, which does not use a fixed rate.
Could you provide some details on your model, compared to how scikit was configured?
Also, can you provide a link to the dataset you used? It’s not the same one used in the Module 2 assignment.
I wasn’t able to find that dataset in MLS Course 1.
Update:
After a search online, I think you’re using this dataset from Kaggle:
…where you are only using the “YearsExperience” input feature, and the “Salary” output.
I implemented a fixed-rate gradient descent for that dataset.
Here is the plot of the dataset and fit:
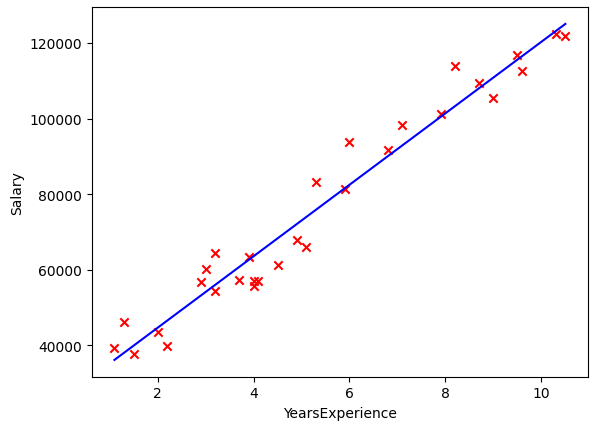
I got the following weights and final cost (2,500 iterations, learning rate 0.01):
w = 9,597.8
b = 24,796.02
Cost 15,639,934.60
So I suspect you may have normalized the dataset before you ran your gradient descent code.
You can change the learning rate and number of iterations over a fairly wide range, and get essentially the same results. Small variations in the weight and bias do not substantially change the final cost.
I would also very much like to hear from you for Tom’s questions. On top of that, you may also check the trained model’s n_iter_ attribute and see if it had stopped earlier than expected.
As a cross-check, i implemented the Normal equation (which provides a direct solution for the weight and bias for linear regression).
Here are the results (b, w and the cost):

So by fixed rate, I think you mean I have fixed the learning rate and ran the algorithms for fixed number of iterations. I definitely did that. And yes you correctly pointed out I used sgd with scikit learn. Is that why it is different ? How is stochastic gradient descent different from the one implemented, I ran both of them for same number of iterations and same learning rate. I didn’t know what initial values of w and b, the scikit’s implementation was using. But in my implementation I used w=0, b=0 and w=1 and b=0. Nothing changed.
I’m afraid, I haven’t used any particular stopping criteria (if you mean the iterations), I just ran for certain number of times. 5000 iterations actually.
And yes, I did some optimization- I just divided the salaries with 1000 so that numbers were not too big. But I did the same for scikit’s inputs
So here is what I can say in short-
- I divided salary by 1000 but gave these values to both of the implementations.
- I ran both the implementations for 5000 iterations
- I did not use any stopping criteria for my implementation, it just gave the output after working for 5000 iterations.
- I used fixed rate for fixed number of iterations in my iterations.
Yes, this is the dataset that I used.
So you have got w and b as 9597.8 and 24796. But you didn’t divide by 1000. I got w as 9.449 and b as 24.84. This is pretty close. So the difference was due to sgd? If I want to implement fixed rate gradient descent in scikit the what can i use? Also, which one is better the sgd or the fixed rate one? Is cost at the end is a good parameter for comparison?
I have also implemented a model using scikit-learn LinearRegression.
Internally this isn’t SGD, it’s ordinary least squares. So I would expect it to give very similar results to the Normal equation.
Here are the results for scikit_learn:
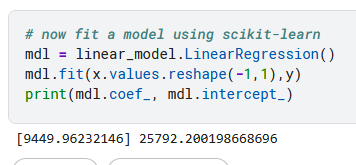
These are indeed identical to the Normal equation.
I’ll try a bit of work with SGD next.
Yes I got the same cost as well. But I want to know this as well-- This cost seems very high right? There will be a lot of deviations in the the predictions then right?
The takeaway so far is that the solution for this system isn’t very critical as to the weight and bias values. There are a wide range of values that give a useful fit.
If you use different numerical methods (like batch fixed-rate GD or SGD), you can expect to get different results. Numerical calculations with limited-precision values are not mathematically perfect. They’re just “good enough” for most purposes.
No. The magnitude of the cost is not important. You only need to find the weight and bias that give the lowest cost. It does not have to be a small value.
This dataset has a lot of variance, and a linear model does not give a very nice fit.
Note also that you’re only using one of the two features that are in the dataset. It would be interesting to see if the model performs better if you use both features.
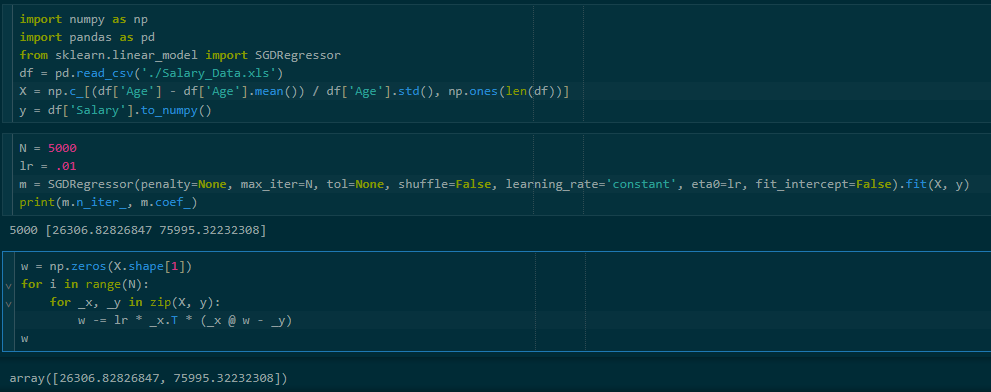
I have a column of ones as the last column of X so that the bias is the last item of the weight array. The rest should be clear.
@Saat, you may want to compare my arguments for SGDRegressor with yours.

I was only letting @Saat know that it’s possible that both match each other, so I didn’t optimize any parameter but that’s the better thing.