Hello, I am having trouble to understand this line of code for masking
np.where(m, dots,np.full_like(dots, -1e9)). I would appreciate to get some help.
I played with the example below from ungraded lab 1:
q = create_tensor([[1, 0, 0], [0, 1, 0]])
display_tensor(q, ‘query’)
k = create_tensor([[1, 2, 3], [4, 5, 6]])
display_tensor(k, ‘key’)
m = create_tensor([[0, 0], [-1e9, 0]])
display_tensor(m, ‘mask’)
if m is not None:
dots = np.where(m, dots,np.full_like(dots, -1e9))
so this is my m:
[[ 0.e+00 0.e+00]
[-1.e+09 0.e+00]]
this is my dots before mask:
array([[0.57735027, 2.30940108],
[1.15470054, 2.88675135]])
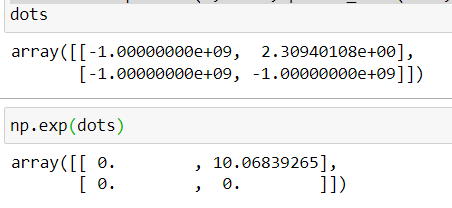
this is my dots after mask:
array([[-1.00000000e+09, -1.00000000e+09],
[ 1.15470054e+00, -1.00000000e+09]])
So I am guessing this line of code np.where(m, dots,np.full_like(dots, -1e9))
is saying, where m is 0, we replace with a large negative number -1e9, where m is not 0 (that’s below the diagonal) we keep it. Am I right?
but I thought we were to mask with a matrix like this
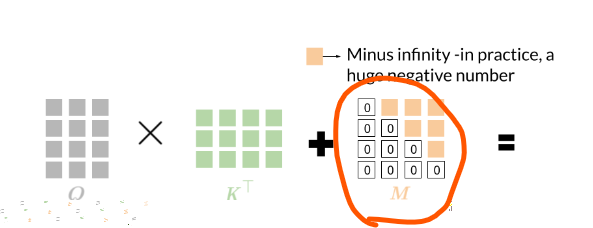
so shouldn’t the mask m be like
[[0,inf]
[0,0]] instead of the one:
[[ 0.e+00 0.e+00]
[-1.e+09 0.e+00]] from the lab?
if I follow the picture, my line of code should be like:
dots=dots+
[[0,inf]
[0,0]]