The way the cost function is constructed is through using the \hat{y}-y difference (this yields a proper pair of w,b after gradient descent. What if (instead), we took the difference between \hat{y} and the closest point to the hyperplane? Would it then, after minimizing the sum of squared lengths, give us the same w,b?
ps: I am referring to the length of the line segment , that goes straight to the line or plane, vertically. I hope it is understood.
With the squared error loss function, we first find the difference between \hat{y}^{(i)} and y^{(i)}. This difference then defines the cost function that we are trying to minimize.
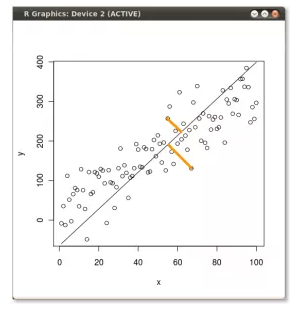
What you are suggesting would lead to a different kind of cost function - The closest distance between {y}^{(i)} and the predicted line (\hat{y}^{(i)} = \vec{w}.\vec{x}^{(i)}+b) is the perpendicular distance from y^{(i)} to the predicted line \hat{y}^{(i)}, and this would be different from (\hat{y}^{(i)} - y^{(i)}). Consequently, we would be minimizing a different cost function and hence i would expect the final value of w and b to be different from what we would have found with the original cost function.
I guess the only way to know for sure is to compute this. Intuitively i feel it should yield same w,b after minimizing. One big issue is computing the partial derivatives with respect to w and b. They are monsters and I think I already understand why this metric was / is not used.
In fact, let me qualify my earlier statement. The Cost Function as per what you have suggested is definitely going to be different from the orginal Squared Error Cost function.
Would this lead to the same w,b as in the original case, after Gradient Descent? - I would leave it open, with the expectation that it does not have to come out to be the same ALWAYS.
I see it primarily dependent on one argument - For a particular value of (w,b) if the original squared error loss \sum (\hat{y}^{(i)} - y^{(i)})^2 is minimum, would \sum (\perp distance between \hat{y} and y^{(i)})^2 also be minimum?
Thanks for the comment. I wanted to say, this was definitely not a suggestion, it was a question only.
How would you distinguish the benefit difference between two cost functions in general? You seem pretty certain in your statement. Maybe backtesting or is there some other metric as well?
Hey Kosmetsas, I think about this again this morning, and concluded that I was wrong. They are not mathematically equivalent. Vertical distance is different from perpendicular distance.
Agreed. Taking the perpendicular distance as error considers errors in both features and label, whereas the vertical distance considers only the label, so perhaps the decision of which one to use would depend on how confident we are on the feature measurements, and perhaps also how related are the feature errors?
OK. The use of perpendicular distance is called the Total least squares, as opposed to Ordinary least squares.
This paper studied TLS, and its conclusion isn’t fully in support of TLS over OLS. The author concerns the use of TLS in climate study. Link here if you have time to read it. i didn’t read it in full so i am not sure if we can summarize out in what scenario is TLS a nice choice.
There is probably a situation that TLS and OLS won’t produce different result, which is when the predicted variable is for the purpose of ranking such that only the relative ordering is important. In this case, the consideration probably goes to computation.
However, I don’t oppose to TLS, and indeed I am wondering whether TLS might help me compare features in one of my current work.
Hey @rmwkwok,
Can you please elaborate on the below point?
How can there be “errors” in features? Aren’t the features supposed to be given to us? I can only think of inconsistencies made during curating the dataset as the “errors”. If that’s the case, then how can we know that the perpendicular distance instead of the vertical distance will model those errors at all ?
Hi @Elemento, there can be random measurement errors in features such as length measured by a ruler, weight by a scale; or statistical uncertainty in aggregated features such as averaged sales over any length of period, or in features that are stochastic in nature such as the level of noise next to a major traffic road or wind speed.
Hey @rmwkwok,
So if these are inconsistencies in features recorded while curating the dataset, how can the perpendicular distance instead of vertical distance possibly model these errors, since these are completely stochastic? In other words, isn’t it completely possible for either of the 2 distance computations to outperform the other in this scenario?
Considering a real estate market dataset, I am guessing, one could use a weighted combination of both methods on test data, and check if attenuation bias cancels out. I have no real word experience, i am just guessing.
Doing this is fine, but its a different problem that we would be solving - Whichever problem we are trying to solve, we need to find a method that best suits our purpose.
Finding a line that minimizes the distance from all the actual points
Vs
Finding a line that minimizes the projection on to it from all the actual points
Hey @Kosmetsas_Tilemahos,
I completely agree with @shanup. At the time of inference, when we predict y for an unseen data example, we take x as it is, so, at the time of training, we should follow the same course of action too. If we train our model in such a way that it tries to “find a line that minimises the projection from all the actual points”, we are essentially modifying x at the time of training, something which seems like logically incorrect to me. I hope this helps.