Entropy H(p_1), H(p_2),H(p_3)… etc will all get the same entropy value for a given node. The entropy formula is simplified in the above slide to make it easy to understand the calculation in the below slide
Entropy is more a property of node so for a given node it will be same. If nodes have notations like [C_1,C_2,C_3,......,C_J] and k classes in dataset then Entropy for given node C_j should be
H(C_j) = -p_0log_k(p_0) -p_1log_k(p_1)+.......-p_{k-1}log_k(p_{k-1})
here p_0 is fraction of class 0 at the node we are calculating entropy.
and p_1 is fraction of class 1 at the node we are calculating entropy etc
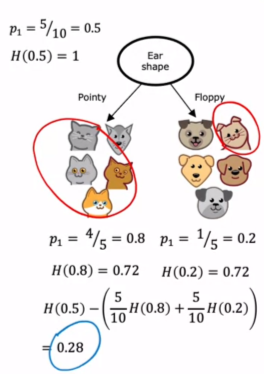
The information Gain formula should be
IG = H(C_{parent}) - (w^{left} H(C_{left}) + w^{right} H(C_{right}))
Here w^{left/right} = (Total number of elements in left/right node)/(Total Number of elements in parent node)
For Example lets consider dataset [cat1, cat2, cat3, dog1, dog2, dog3, dog4, mouse1, mouse2]
There are 3 cats, 4 dogs and 2 mice. Lets consider a decision tree as below

Entropy for C_{parent} node is
H(C_{parent}) = -p_{cat}*log_3(p_{cat}) -p_{dog}*log_3(p_{dog}) -p_{mouse}*log_3(p_{mouse})
here p_{cat} = 3/9, p_{dog} = 4/9, and p_{mouse} = 2/9
H(C_{parent}) = (-3/9 * log3(3/9)) - (4/9 * log3(4/9)) - (2/9 * log3(2/9)) = 0.966
The above entropy will be “1” if all the elements of the dataset are equal, i.e, 3 cats, 3 dogs, 3 mice. Similarly, you calculate H(C_{left}), H(C_{right})
H(C_{left}) = (-2/5 * log3(2/5)) - (1/5 * log3(1/5)) - (2/5 * log3(2/5)) = 0.96
H(C_{right}) = (-1/5 * log3(1/5)) - (3/5 * log3(3/5)) - (0/5 * log3(0/5)) = 0.57
Finally, Information gain is calculated by
w^{left} = 5/9, w^{left} = 4/9
IG = H(C_{parent}) - (w^{left} H(C_{left}) + w^{right} H(C_{right}))
IG = 0.97 - (5/9 * 0.96 + 4/9 * 0.57) = 0.183
Without context of how other features will perform we cant say if the above IG is good or bad but the right node seem to do good job of isolating dogs at least but we also have to consider that more elements are in left node and their entropy is very high which is bad.
