The second one is: RuntimeError: expected device cpu but got device cuda:0
I get this line when I try to train the Pix2Pix. If I change the device to cpu, the error disappear but the training seems to freeze from the beginning.
It’s great that you were able to tackle your first problem. Concerning your second issue, when you switch to CPU, the training takes a long time because:
GANs are computationally expensive
CPUs are slow, right?
Perhaps it is not freezing as you claim, but rather training at a very slow rate.
Since the assignment you’re referring to doesn’t need you to submit any files, your assignment was accepted as long as the code was valid (logically, syntactically, etc.).
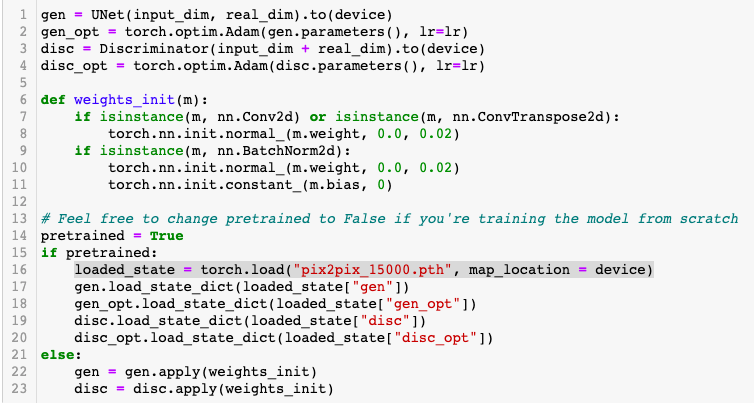
Firstly, thanks for asking this doubt because it has got me an idea to solve this issue.
Just add the parameter map_location = device while you are loading the pre-trained checkpoint. Also, make sure that you have set the device to cuda in the training preparation step. Check Line#16 for setting the map_location parameter.
While calculating the adversarial loss, the ones tensor is getting created in CPU using statement torch.ones(pred.shape). You need to send it to the required device while training the model.
So, replace that adversarial loss calculation statement with the following statement: