Hello everyone!
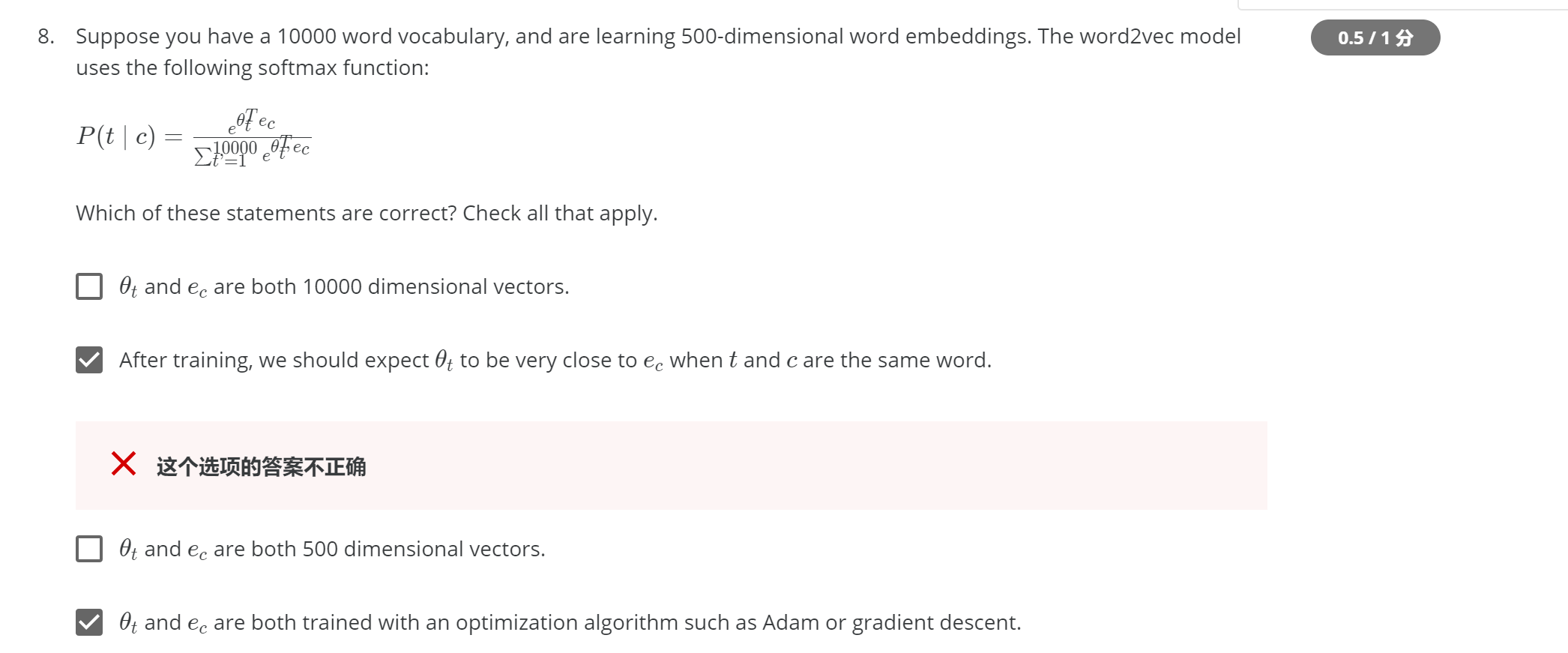
I want to ask why it is not true that After training, we should expect θt ,e_c to be very close when t and c are the same word.
Could you tell me the reason? Thanks.
Hello everyone!
I want to ask why it is not true that After training, we should expect θt ,e_c to be very close when t and c are the same word.
Could you tell me the reason? Thanks.
Hi Robert,
This is what I found:
“if two words are the same then the similarity will be one and probability will be 1”
So for me if they are the same word, the vectors should be the same, not close.
In that formula it is a bit confusing that they are using t for both the word and the index of the sum. It is better explained here.
Best,
Rosa
Hi Rosa,
Thank you so much for your detailed reply. Very helpful!