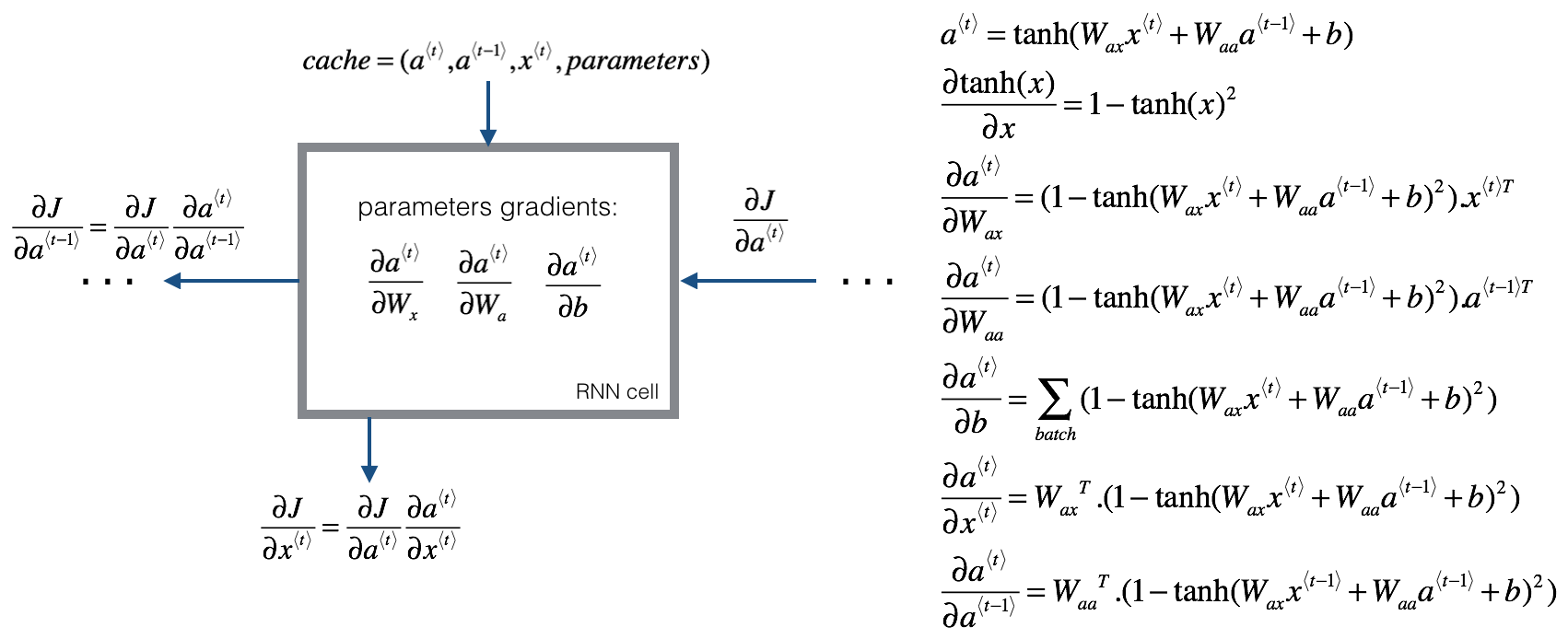
I am trying to implement simple RNN from scratch to understand the calculations step behind each implementation. Forward Propagation seems straightforward, but backward propagation seems very difficult. Especially the dimension does not match…
def rnn_forward(self, e) :
for t in range(self.T_x - 1) :
# single (n_x, n_m) m is training set size in time
xt = self.cache['X'][:, :, t]
# hidden state of previous step
a_prev = self.cache['A'][:, :, t]
# hidden state of next step is caculated by following weights and biases.
a_next = tanh(np.dot(self.parameters['W_aa'], a_prev) + np.dot(self.parameters['W_ax'], xt) + self.parameters['b_a'])
# using softmax as final activation
yt_pred = softmax(np.dot(self.parameters['W_ya'], a_next) + self.parameters['b_y'])
self.cache['A'][:, :, (t + 1)] = a_next
self.cache['Y_pred'][:, :, t] = yt_pred
def rnn_backward(self, e):
# cost function derivative
self.cache['dY_pred'] = - (self.cache['Y'] / self.cache['Y_pred'])
# initialized da
da_next = np.zeros((self.n_a, self.m))
for t in reversed(range(self.T_x - 1)) :
# dimension seems to be (n_y, n_m)
print(self.cache['dY_pred'][:, :, t].shape)
# dimension seems to be (n_y, n_m) as well
print(softmax_backward(np.dot(self.parameters['W_ya'], self.cache['A'][:, :, t]) + self.parameters['b_y']).shape)
# following computation would have issues? da_prev is expected to have dim (n_a, n_m), but the dot of (n_y, n_m) and (n_y, n_m) don't give me (n_a, n_m)
da_prev = np.dot(self.cache['dY_pred'][:, :, t], np.dot(self.parameters['W_ya'].T, softmax_backward(np.dot(self.parameters['W_ya'], self.cache['A'][:, :, t]) + self.parameters['b_y']))) + da_next
self.cache['dW_ya'] += np.dot(self.cache['dY_pred'][:, :, t], np.dot(softmax_backward(np.dot(self.parameters['W_ya'], self.cache['A'][:, :, t]) + self.parameters['b_y']), self.cache['A'][:, :, t].T))
self.cache['db_y'] += np.dot(self.cache['dY_pred'][:, :, t], softmax_backward(np.dot(self.parameters['Wya'], self.cache['A'][:, :, t]) + self.parameters['b_y']))
self.cache['dW_aa'] += np.dot(da_prev, np.dot(tanh_backward(np.dot(self.parameters['W_aa'], self.cache['A'][:, :, (t - 1)]) + np.dot(self.parameters['W_ax'], self.cache['X'][:, :, t]) + self.parameters['b_a']), self.cache['A'][:, :, (t - 1)].T))
self.cache['dW_ax'] += np.dot(da_prev, np.dot(tanh_backward(np.dot(self.parameters['W_aa'], self.cache['A'][:, :, (t - 1)]) + np.dot(self.parameters['W_ax'], self.cache['X'][:, :, t]) + self.parameters['b_a']), self.cache['X'][:, :, t].T))
self.cache['db_a'] += np.dot(da_prev, tanh_backward(np.dot(self.parameters['W_aa'], self.cache['A'][:, :, (t - 1)]) + np.dot(self.parameters['W_ax'], self.cache['X'][:, :, t]) + self.parameters['b_a']))
da_next = np.dot(da_prev, np.dot(self.parameters['W_aa'].T, tanh_backward(np.dot(self.parameters['W_aa'], self.cache['A'][:, :, (t - 1)]) + np.dot(self.parameters['W_ax'], self.cache['X'][:, :, t]) + self.parameters['b_a'])))
as the comment in the code, I can’t seem to implement the backprop correctly. The dimension doesn’t go together for da_prev to result in (n_a, n_m) correctly… Did I miss out on something?
Thank you!