I have a doubt about user_train scaling values.
Let’s consider the first user in user_train in the original scale.
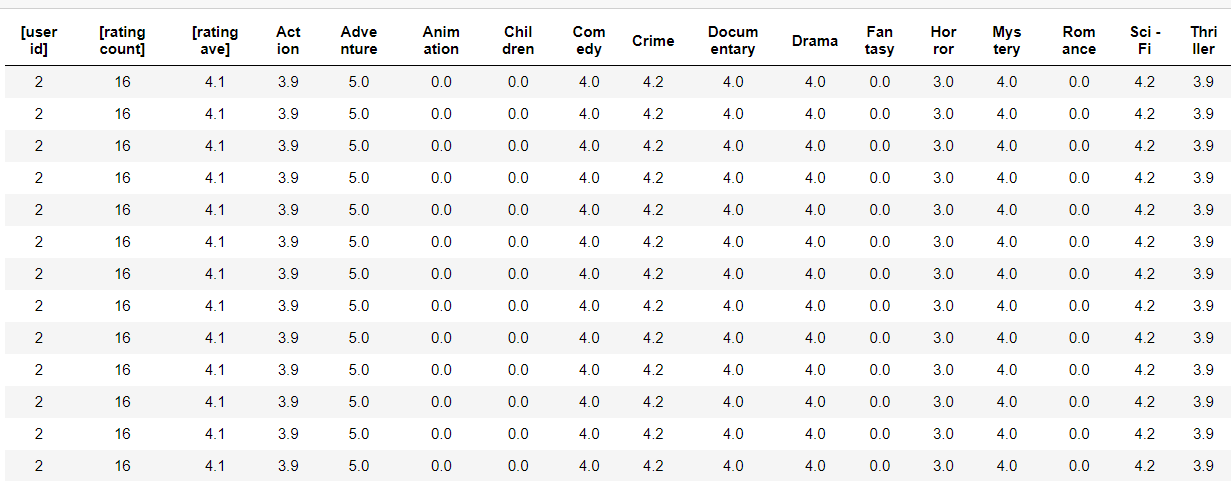
When we observe in the original scale, we could see that the first few rows of user_train belong to user 2. Lets now consider only user 2
We could see that all these rows belonging to user 2 are similar because the user vector is the same for all the movies the user rated. And hence the similar rows for each user.
So, from my understanding, the rows of user_train of user 2 represent the reviews/ratings of user 2 for each movie the user 2 rated.
Let’s now consider the first few rows of item_train.

According to me, the matrix item_train contains, the respective movies which were rated by user 2, where each row contains one hot encoding for each genre(duplicated rows for each of the movies rated by user 2 with different encodings for the genre)
If my understanding is correct, So now comes to the actual question.
If the user_train contains the same rows and same feature values for user 2 for all the movies,
when we perform standard scaling of input features(which is performed column-wise), then values in each of the columns for this user 2 be the same right?
Cuz, in standard scaling, the mean and std for a column are calculated, and the same mean and std are subtracted from all the feature values in a column, right? How come they are different?

Kindly correct me if I comprehended it wrongly