shubhsr
December 22, 2022, 2:27am
1
In pre_attention_decoder_fn and in other functions, I am not able to use tl.ShiftRight layer is by default nested inside the Serial Combinator. What to do? Anyone can please help.
Hi @shubhsr
I have encountered the issue in the past and cannot quite remember how I solved it. I think it was something with layer initialization or input size, but I’m really not sure
By quick search I can find these issues were posted:
opened 06:06AM - 28 Jun 21 UTC
closed 03:59AM - 05 Jul 21 UTC
### Description
I am trying to build an attention model but Relu and ShiftRig… ht layer by default gets inside the Serial Combinator.
This further gives me errors in training.
### Environment information
The code is from the Coursera NLP Specialization Attention Model Course, it worked in the Coursera Jupyter environment but now I am trying in Kaggle notebooks the issue arises
part of code
### Code:
```
def DecoderBlock(d_model, d_ff, n_heads, dropout, mode, ff_activation):
# feed-forward block
feed_forward = [
tl.LayerNorm(),
tl.Dense(d_ff),
tl.Relu(),
tl.Dropout(rate=dropout, mode=mode),
tl.Dense(d_model),
tl.Dropout(rate=dropout, mode=mode)
]
# residual block
residual = [
tl.Residual(
feed_forward
)
]
return residual
print(DecoderBlock(d_model=512, d_ff=2048, n_heads=8, dropout=0.1, mode='train', ff_activation=tl.Relu))
```
### Output
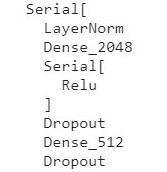
### Expected Output should be
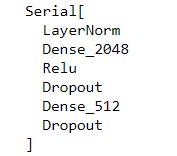
**Similar issue arises with tl.ShiftRight()**
### Code
```
def TransformerLM(vocab_size=33300,
d_model=512,
d_ff=2048,
n_layers=6,
n_heads=8,
dropout=0.1,
max_len=4096,
mode='train',
ff_activation=tl.Relu):
positional_encoder = [
tl.Embedding(vocab_size, d_model),
tl.Dropout(rate=dropout, mode=mode),
tl.PositionalEncoding(max_len=max_len, mode=mode)
]
serial = tl.Serial(
tl.ShiftRight(mode=mode),
positional_encoder,
tl.LayerNorm(),
tl.Dense(vocab_size),
tl.LogSoftmax()
)
return serial
print(TransformerLM(n_layers=1))
```
### Output:
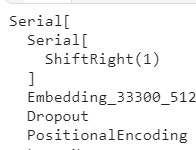
### Expected Output

opened 11:07AM - 10 Sep 21 UTC
### Description
Activation layers appear to be nested inside their own Serial… combinators by default. Is there a reason for this?
Also found it mentioned on Stack Overflow with a workaround but no answer: https://stackoverflow.com/questions/68177221/trax-tl-relu-and-tl-shiftright-layers-are-nested-inside-serial-combinator
### Example
```
import trax.layers as tl
model = tl.Serial(tl.Dense(32),
tl.Relu(),
tl.Dense(1))
print(model)
# Output
Serial[
Dense_32
Serial[
Relu
]
Dense_1
]
# Expected output
Serial[
Dense_32
Relu
Dense_1
]
```
...
### Environment information
```
OS: Debian 10
$ pip freeze | grep trax
trax==1.3.9
$ pip freeze | grep tensor
mesh-tensorflow==0.1.19
tensorboard==2.6.0
tensorboard-data-server==0.6.1
tensorboard-plugin-wit==1.8.0
tensorflow==2.6.0
tensorflow-datasets==4.4.0
tensorflow-estimator==2.6.0
tensorflow-hub==0.12.0
tensorflow-metadata==1.2.0
tensorflow-text==2.6.0
$ pip freeze | grep jax
jax==0.2.20
jaxlib==0.1.71
$ python -V
Python 3.7.3
```
I cannot pinpoint the exact problem and if I remember how I got around it I will post it.
Cheers
shubhsr
December 24, 2022, 6:14pm
3
The solution worked, but still, the same problem is in tl.AttentionQKV(…) in NMTAttn function while running the AttentionQKV layer

