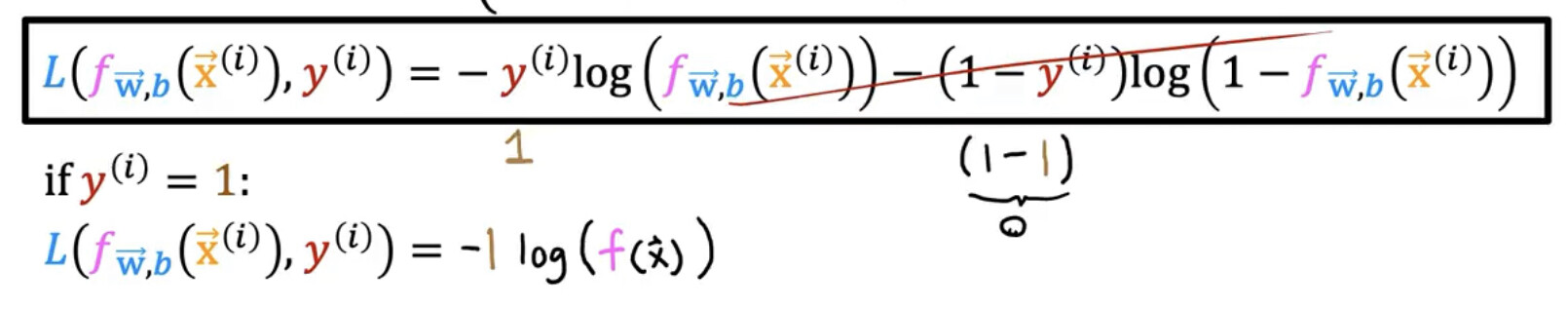Could some please explain me how one comes to the rewritten form of the “logistic loss function” which is part of the overall “logistic cost function” (see “Optional Lab: Logistic Regression, Logistic Loss”)?
The logistic Cost Function has a form like this L(\hat{y}, y) = \begin{cases} - \log(\hat{y}) & \textbf{if} \, y = 1 \\ - \log(1 - \hat{y}) & \textbf{if} \, y = 0\end{cases}
where \hat{y} is f_{W, b} (x) and y is the true values.
which is exactly equivalent to the other form: L(\hat{y}, y) = -y \log(\hat{y}) - (1 - y) \log(1 - \hat{y})
if you have y = 0 then the last expression results in -\log(1 - \hat{y}) because 1 - y is just 1 when the y = 0. and has the form -\log(\hat{y}) if we set y = 1 that because 1 - 1 = 0 there for the other side is just will be zero.
Now, in terms of code. the two cases can be done in this form
from math import log
def loss_1(y, yhat):
cost = 0
for i in range(len(y)):
cost += ((-y[i] * log(yhat[i])) - ((1 - y[i]) * log(1 - yhat[i])))
return cost
def loss_2(y, yhat):
cost = 0
for i in range(len(y)):
if y[i] == 1:
cost += (-log(yhat[i]))
elif y[i] == 0:
cost += (-log(1 - yhat[i]))
return cost
y = [1,0,1,0,0]
yhat = h = [0.01,.99,.9,.01,.1]
loss_1(y, yhat) # 9.431111739145337
loss_2(y, yhat) # 9.431111739145337
Both are the same and will give the same results. I hope this makes it clear to you.
Thanks @Moaz_Elesawey! But how exactly do you come to this equivalent? I understand what happens for L if you set y to 1 and 0 for the mentioned equivalent. But I do not understand how Andrew Ng comes to this equivalent.
I know from the “squared error cost function” that you do a kind of…
ŷ - y
where
ŷ = prediction/estimate of the actual true value y and
y = target value or output (= real, true value of the training example).
Now, I see what you want to understand. I was going to sketch it up on paper and sent it to you but I found this blog post on the towrdsdatascience website that explains it better.
Professor Andrew Ng calls the logistic cost function a simplified cost function. I did not understand why or what is simplified?
What I understood is that the terms for y=1 and y=0 are simplified from the more complex logistic loss function formula I mentioned above (see the statistical principle called “maximum likelihood estimation”).
Swap your descriptions. The two formulas are the complex form and the one line is the simplified form. It’s simplified because when you’re training the function to find better weights and biases you can run the test data and answer through one test instead of two. During training we know the value of y. That allows use to discard one half of the equation based on if it (y) is 0 or 1.
when y = 1 we’re subtracting 1 from one making it -0 * log(1-f(x)). That zero eliminates the rest of the equation from mattering. So we use just the first half to calculate.
tl;dr - Single line logistic regression function is simplified for computer consumption, not human.
@Daniel_Blossey Thanks for the reply. I suggest you go back and check out the videos on this subject. Andrew Ng has a pattern of introducing an idea using math then modifying the idea so it’s easier for a computer to understand. You might notice that Andrew talks about the two functions first before “simplifying” it to one line of math that seems overly complex to us.
@Moaz_Elesawey did an awesome job of demonstrating the two functions in code. When we use the word “simplify” we aren’t making the functions easier for a human to understand. We’re writing it in an easier way for the computer to solve quickly.
I’m not sure what kind of background you have. Generally people approach ML from either Math or Computer Science background. I fall on the CS side. An if statement seems like an easy thing to do. If you run it once the cost of it is so low that it’s imperceptible to a human. But it does have a cost, a VERY VERY small cost, but a cost none the less. We’re using the loss function to help train the weights and biases. Sometimes that takes hundreds of thousands of iterations. Sometimes millions or billions of iterations depending on your data. If you add up the small cost of checking if y = 0 every single time you start getting into milliseconds of time wasted performing that check. When you’re running billions of iterations of training data you might actually start to get into the minutes, hours or perhaps longer spent just deciding if y = 0. By removing that step and using math to decide which one to do by multiplying one of the functions by 0 we are actually saving that time.
I don’t know if you’ve done the final assignment for Week 3 yet. I just did it last night. Our data set is relatively small. Maybe a few hundred entries. But it still takes about 20 seconds to train over that data running only 10000 iterations. Makes me curious how much longer it would take using if statements to pick which function to run. Over 10k iterations it’s probably only a few ms longer.
OK, this is acceptable and plausible for me because it’s about performance and calculation time that makes the easier and human readable looking expressions more complex in computing:
Complex logistic loss function (= difficult to read by the machine):