The unit test fails with the error below:
Test your function
w4_unittest.test_approximate_knn(approximate_knn, hash_tables, id_tables)
Wrong chosen neighbor ids.
Expected: [51, 2478, 105].
Got: [51, 105, 154].
It’s interesting though that the documents 105, 2478 and 154 all have the same cosine similarity with doc_id=0 :
cosine_similarity(document_vecs[0],document_vecs[154])
0.9999999999999998
cosine_similarity(document_vecs[0],document_vecs[2478])
0.9999999999999998
cosine_similarity(document_vecs[0],document_vecs[2478]) == cosine_similarity(document_vecs[0],document_vecs[154])
True
What’s even more intersting is that the embedding vectors for these tweets are identical:
all(get_document_embedding(all_tweets[0], en_embeddings_subset) == get_document_embedding(all_tweets[2478], en_embeddings_subset))
True
There is a bug in this unit test: it checks for a particular list of vector ids (not vectors) returned by nearest neighbors; as there are multiple vectors in all_document_vecs with exactly same coordinates, the selection of nearest k ids is ambiguous.
If your nearest neighbors function puts out the ids for identical vectors in the ascending order, like mine did – the unit test will fail and you’ll need to tweak it to return them in the descending order.
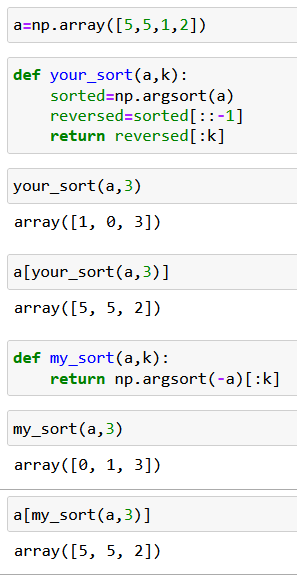
Here is a simple use case to verify your implementation:
Hey @Dmitry_Krylov,
In your nearest_neighbor function, you are supposed to reverse the order of the sorted_ids, as mentioned in the markdown. The unit-tests are designed keeping that in mind. If you have done that, then I don’t think that the unit-tests will fail. I hope this helps.
Cheers,
Elemento
Hmm @Elemento , Just curious where in the markdown it mentions the reverse order.
Hey @Dmitry_Krylov,
If you check out the comments in the nearest_neighbor function, you will find the below comment:
Reverse the order of the sorted_ids array
Additionally, if you check out the Hints section for this function, you will find out the reason as to why this is necessary. I hope this helps.
Cheers,
Elemento
I think it would help if the requirements are stated explicitly, in either markdown or required function signature especially for those who wish to write their own code without looking at hints.
As you can easily check, there are 7 tweets with the identical cosine similarity with tweet (doc_id=0). When 3 out of these 7 are selected, it should be up to implementation which ones to pick (they all have the same coordinates by the way). So the unit test should take this into account and just use vector coordinates, not their indexes, for assertion. Otherwise perfectly valid code would fail the unit test. In the suggested solution reversing the order is needed for the suggested approach, but I can use argsort on negated array without the need for subsequent reversing. Functionaly these methods are very similar except when the same value exists in the array more than once. A code snippet below illustrates this - note a different order for the two indexes value 5.
Hey @Dmitry_Krylov,
As to why the array should be reversed post the use of argsort, it’s just to put the returned IDs in decreasing order of their similarity with the given vector. As you have mentioned, you can negate the array, and then use argsort as well. But note here that nearest_neighbor implies that vectors with highest similarity should be put first, and I believe that it’s best if left for the learner to figure this out, otherwise, the learners won’t be able to hone their intuitions. So, the fact that the order should be reversed is best suited in the hints section only.
Now, the second thing, i.e., in the case of vectors with the same cosine-similarity, different approaches will give different results, and the unit-tests fail one of that approaches and pass the other one, is definitely a good one. Let me raise an issue regarding this, so that this can be rectified.
Cheers,
Elemento
Hey @Dmitry_Krylov,
I raised this issue with the team. If you take a look at the given code and comments for nearest_neighbor function, you will find that the learners are expected to sort the array in decreasing order of similarity values, in 2 steps:
- Sort the similarity list and get the indices of the sorted list
- Reverse the order of the sorted_ids array
Hence, the team thinks that most of the learners will follow this pattern, and therefore, this issue won’t arise. But if this issue arises in the future, they will rectify this issue as per your proposed fix. Once again, thanks a lot for your contributions.
Cheers,
Elemento