I get the code done and passed, but I still do not understand the dimensions of q, k, v:
q – query shape == (…, seq_len_q, depth)
k – key shape == (…, seq_len_k, depth)
v – value shape == (…, seq_len_v, depth_v)
What is the depth and depth_v?
Is seq_len_k the number of words in the sentence?
Is seq_len_q the number of questions to ask? How is it selected? Is it a super parameter to tune?
Does the … represent the folds pf multi-head computations?
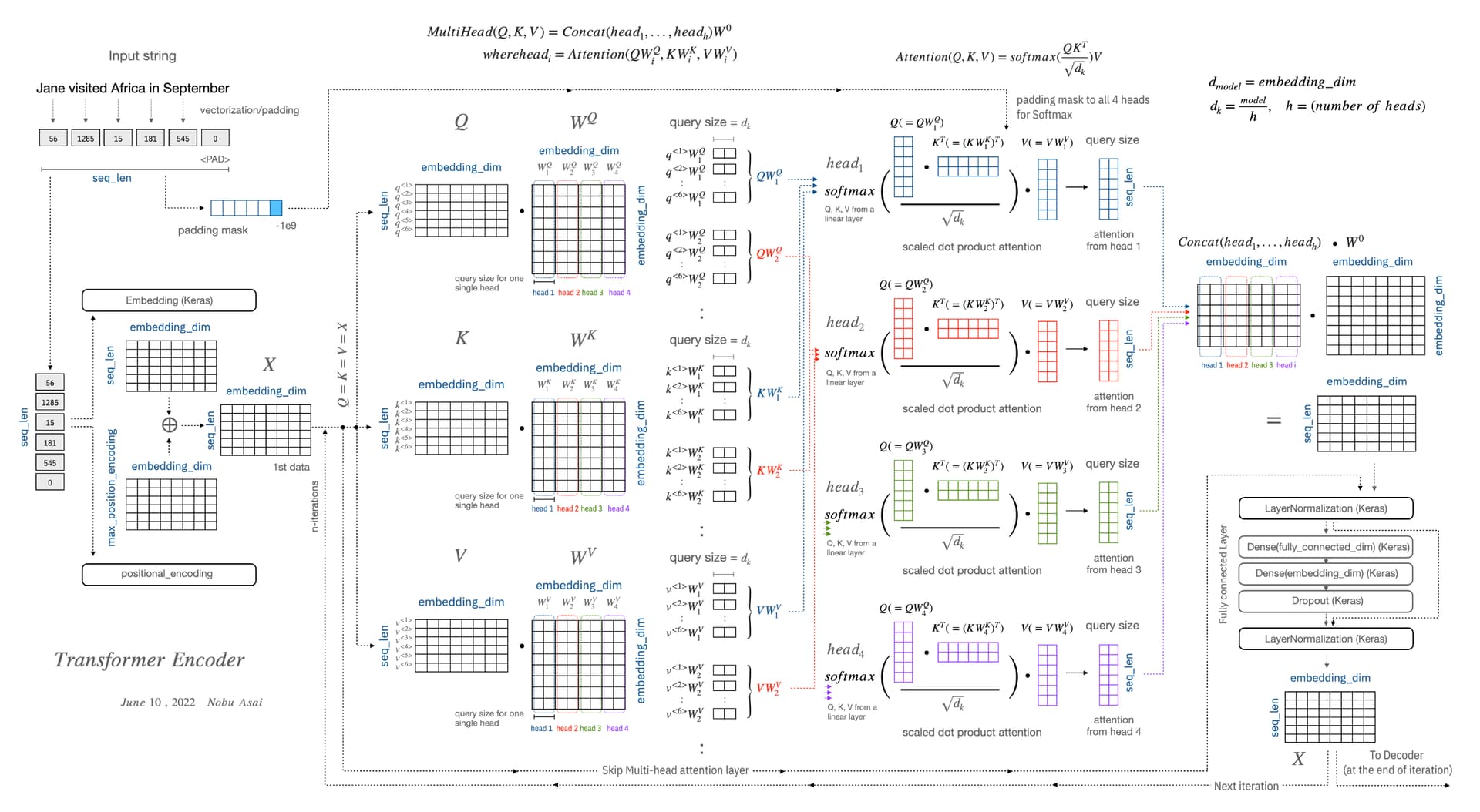
You can see the process for multi-head attention including scaled dot product attention at the center of this diagram.
Most important variable is “embedding_dim” which is equal to “model dimension”, d. Embedding, positional_encoding, fully connected layers and multi-head attention layers are using this value as one of input/output shape of data. (Another key variable is “seq_len”)
(As of today, Jun 22, there are incorrect description about “embedded_dim”. For example, the shape of “3rd parameter for encoder_layer_out” is described as (batch_size, input_seq_len, fully_connected_dim). But, the last one should be “embedding_dim”.)
“query size”, d_k which is “depth” in this assignment is calculated as follows.
d_k = \frac{d_{model}}{h} = \frac{embedding\_dim}{num\_heads}, \ \ \ \ \ num_heads: number of heads for multi-head attention layer
Answers to questions:
depth and depth_v are “query size” which is calculated by the above equation.
seq_len_q, seq_len_k, and seq_len_v are essentially same, and are equal to seq_len. seq_len is “number of words” + padding.
seq_len_q is equal to seq_len, and is “number of words”+padding. If you look at Q, each row of “seq_len” is represented as q^{<i>}. In this sense, it can be also said that “questions to ask”.
“…” is same as other input that we saw in the past exercises, I suppose. In my chart above, it is for a single sample (sentence), which includes multiple words. But, of course, the system can accept multiple samples at one time. I suppose this represents “number of input sentences”.
As you see, this “scaled_dot_product_attention” is not used in this exercise, since it is included in Keras MultiHeadAttension. That makes learners difficult to understand input/output parameters.