we had couple of doubts. Can you please help to answer ?
Suppose if the algorithm wandering around the minimum means, not able to converge means, how i can know that practically such that the algorithm wandering around the minimum in high dimensional space (like plot graphs or based on some value) ?
Suppose if the algorithm stuck in bad local optima means, how we can come to know practically ? Here is my answer for it. Is it correct ? if stuck in local optima means gradients will not be close to zero.
You can tell if it is not converging because the cost does not go down any more. In that case, try a different set of random initial conditions.
Generally speaking, if the cost stabilizes, then you have a solution. Whether that is good enough or not is evaluated by looking at the training and test accuracy that you get. If the solution gives good values for those, then it’s fine. If not, then you need to try again either with different initialization or with different hyperparameters. I gave you the link to the famous Yann LeCun paper on your “saddle point” thread which explains why the problem of bad local optima usually is not that much of a problem.
The direct answer is the gradients will be zero at any local minimum or maximum or saddle point. So the fact that the gradients are zero doesn’t tell you whether the point you found is useful or not. The way you tell that is what I said above: you calculate the training and test accuracy with the model that is produced by that point at which the gradients are zero. The performance you get at that point is either good enough or it’s not. That’s how you tell a “bad local optimum” from a “good local optimum”.
If gradient descent is not converging, then the cost will either diverge (grow larger) or oscillate as opposed to moving monotonically lower.
If you find a local minimum, there is not really any practical way to know if that is the global minimum unless it happens to actually be J = 0. All you can do is try again with different initial conditions and see if you find a lower cost. But if you look at the Yann LeCun paper that I linked on your “saddle point” thread, that makes the point that finding the global minimum is not really what you want in any case: that would represent very serious overfitting on the training set. The overall message of that paper is the reason that Prof Ng tells us in the lectures here in Course 2 that the concern over finding bad local optima is not really that much of a problem in real world sized networks.
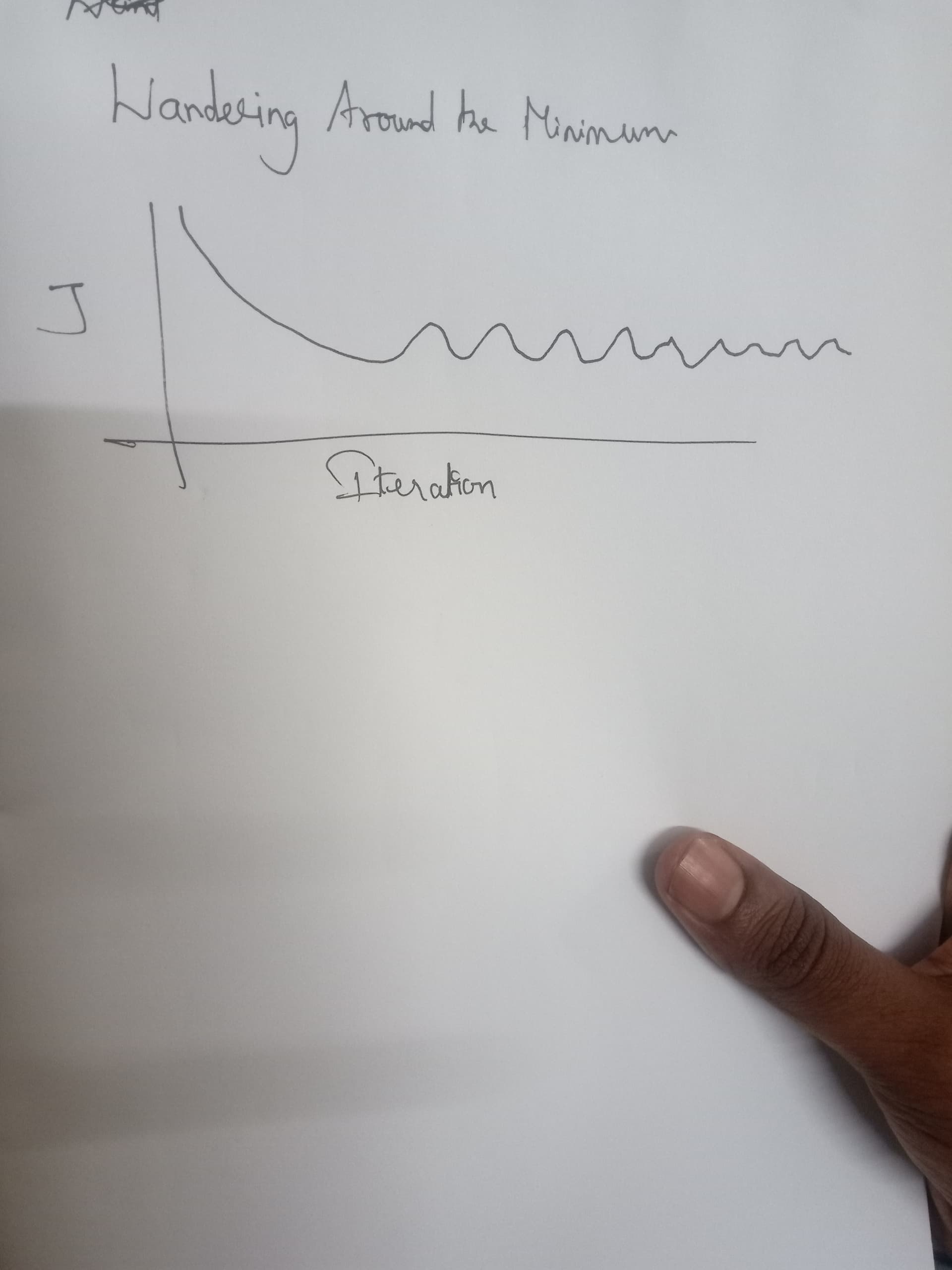
 Below is the right pic for we can say wandering around the minimum right sir ?
Below is the right pic for we can say wandering around the minimum right sir ?