Hey Everyone,
I hope you all are doing well.
Yesterday I completed the Week 1 classes of the Supervised Machine learning module of the ML specialization course, and after learning about the gradient descent algorithm, an optimization technique came into my mind which might be able to solve the below limitation of the current algorithm of identifying Global minimum for a cost function which is non-convex in nature (not bowl shaped).
Please correct me if I am wrong, what I understood from the lecture is that the problem/limitation with the Gradient descent algorithm for non-convex functions is, once you reach a local minima, you will be stuck there and it might be the case that there exists a better local minima in the function.. Basically you might not be able to find the Global minimum.
So, I thought, what if we draw a horizontal line from the local minima which we initially found and check for the points that fall in the intersections of the function plot and the horizontal line. Those points would be then considered as the starting point for the next gradient descent. Once we do it for all, we can check the minimum value between them to identify the global minima or a better local minima.
The plot might look like this. (Sorry for the bad drawing)
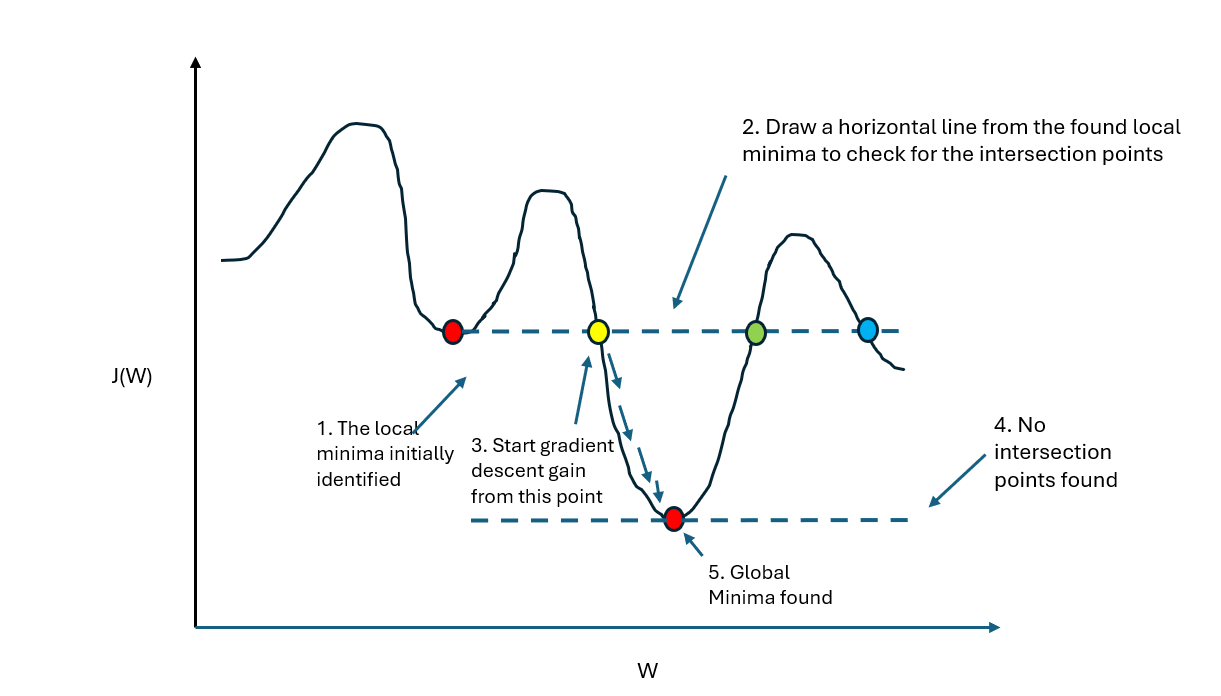
The real world analogy might be like, going by the same example, which is given in the lecture - Imagine you’re hiking and you reach a local valley (local minimum).
You scan the horizon (horizontal line) and see another valley that’s at the same or lower altitude.
I just wanted to share this with you all to get your feedback.