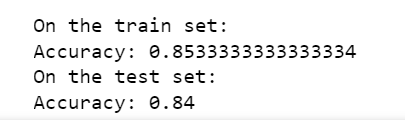
In the second case of the lab where we randomly initialize big values for W, I understand that the cost is high because the values for activation functions in each layer are near 0 or 1.
But when I try running the model for more iterations (up to 100000), why the cost does not continue to decrease and we get beautiful values of W as in the third case when we use he initialization?