Hi,
I didn’t quite well get the intuition about how in the case of high dimensional dW and db, the algorithm ensures slower update in the horizontal direction and faster update in the vertical direction. It is understandable with the assumption b as vertical and w as horizontal but what exactly happens with high dimensional parameters?
Hi, @ShreS.
Sorry for the late reply 
It will simply decrease the step size for large gradients, and increase it for small ones. I don’t think it makes sense to refer to a horizontal or a vertical direction in a high dimensional parameter space (although you can use dimensionality reduction techniques to visualize it).
I would look at the lower dimensional case to build my intuition, and rely on math for the higher dimensional one.
I hope you’re enjoying the specialization 
P.S. Regarding the visualization of loss landscapes, there’s a website I really like.
Hello, I think the intuition provided in the video is a little confusing. Consider the following sequence of gradients:
step 1: dw = +0.0001
step 2: dw = -0.0001
step 3: dw = +0.0001
step 4: dw = -0.0001
step 5: dw = +0.0001
. . .
RMSProp tracks the average magnitude from recent time steps. In our case the average magnitude is 0.0001 and so we divide dw by this number and get the following new gradients:
step 1: dw = +1.0
step 2: dw = -1.0
step 3: dw = +1.0
step 4: dw = -1.0
step 5: dw = +1.0
. . .
so we actually made the oscillations much much worse
The point of RMSProp is not reducing oscillations. The point I think is rescaling gradients. In deep layers, gradients can become very small or very large. RMSProp rescales them to be “around 1”
I think you could actually replace RMSProp with the following simple code and get very similar results:
if dw >= 0: dw = +1
else: dw = -1
Hi, @jiri.314159265.
Sorry for the late reply
You may find this post interesting.
Just using the sign of the gradient is not free of problems.
Good luck with the course
I am not getting it. My understanding was large gradients were a good thing as it reduces loss function and greater step in GD. Why are we penalizing large gradients. “dw” = dL/dw
Hi, @shubham_wazir.
The problem is the (negative) gradient, more often than not, does not point towards the minimum. Large steps in the wrong direction can cause oscillations, as can be seen in the lectures:
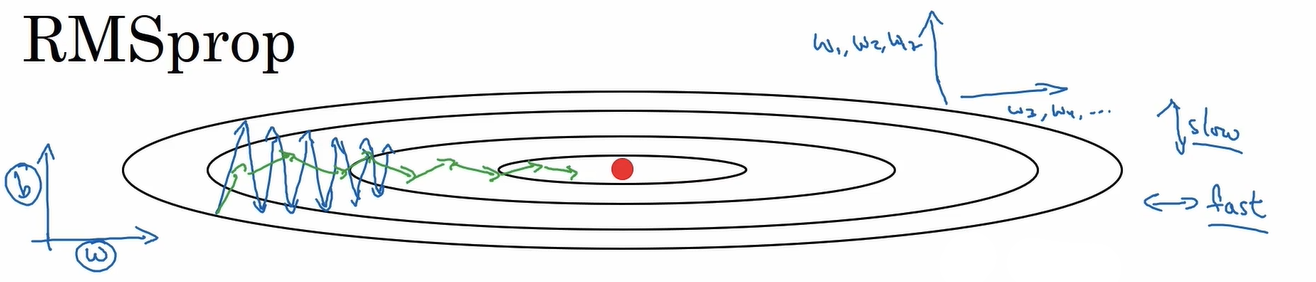
You can play with this simulator to get a better intuition.
Let me know if something is still not clear. Good luck with the course ![]()