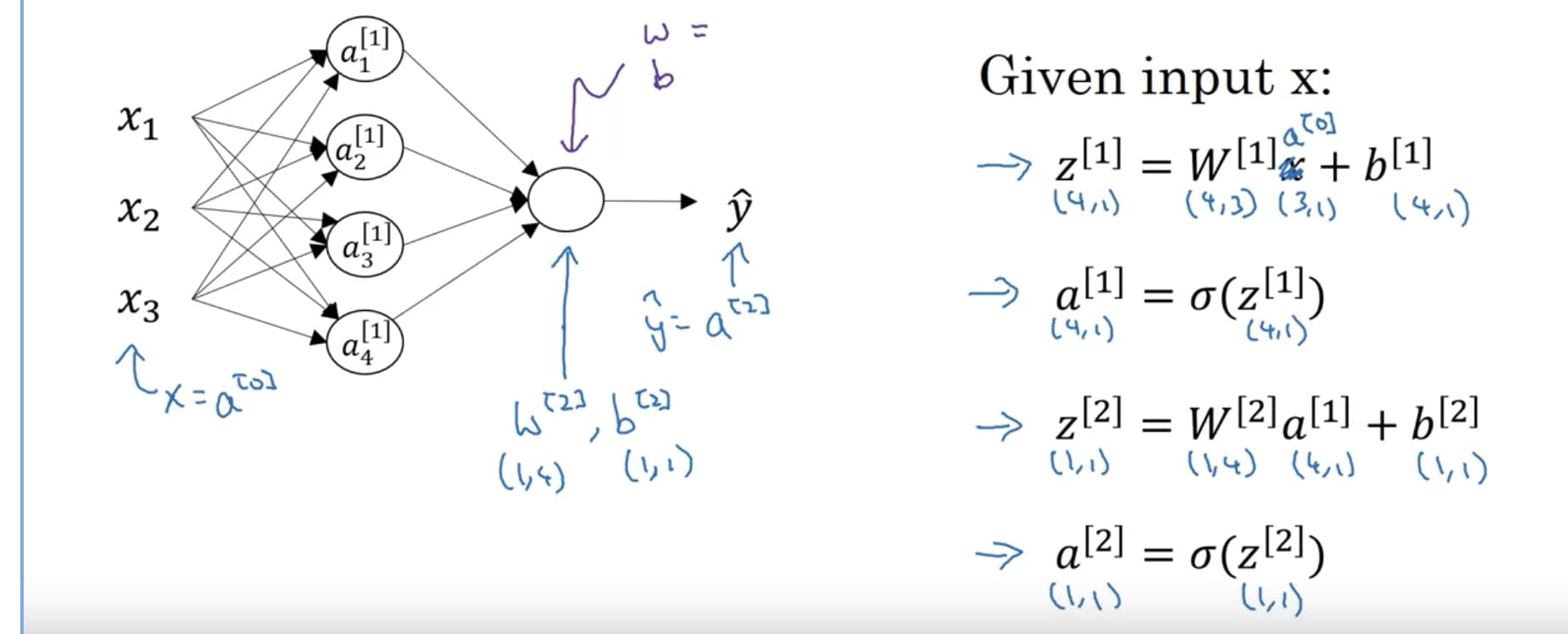
From my understanding, the input layer takes 3 features of an individual from X, so the input layer is merely one individual. These feature values are then put into a linear regression model with wx+b in layer 1, and then thru the sigmoid function into a logistic regression model. What I don’t understand is: if the first node of layer 1 already has values of vector w and it calculated the prediction for training example x given vector w (i.e., y hat), then why is there a need for the other 3 nodes in layer 1?–we already calculated y hat. And from there once it takes all of these y hats, how does it consolidate them into a single y hat in layer 2?
Thank you