Q, K, V structure is not an original technology of Transformer.
Simple “attention” mechanism uses a “Source-Target” type reference model. It only has a direct reference among “target” and “source” like the left-hand side chart below. (A diagram is from FRUSTRATINGLY SHORT ATTENTION SPANS IN NEURAL LANGUAGE MODELING.
But, this direct relationship may not be flexible if “these two are quite similar and should have relations, i.e., attention, but a referred word needs other word to be meaningful”. Then, “source” was separated into “key” and “value”, and “target” was renamed as “query”, just like the right-hand side chart. Later, this key-value pairs are called “dictionary”. Details are in Key-Value Memory Networks for Directly Reading Documents. (In the past work, K-V is also called “memory”.)
So, straightforward implementation of this Q,V,K system is “Source/Target attention”, which is the 2nd MHA in our assignment. In the case of English->French translation, “Source” is Encoder side which has “English” dictionary, and “Target” is Decoder that has French reference sentence (label).
In here,
Q : Target (output from 1st MHA in Decoder, French sentence)
K/V : Source (output from Encoder, English sentence)
(Note that “sentence” is not a list of word, of course. It is “word embedding” + “position encoding”.)
Then, create attention weights to translate English sentence to French sentence.
Now, let’s go to “Self-attention”. (I think starting from “Self-attention” may not be appropriate without having knowledge of Transformer overview.)
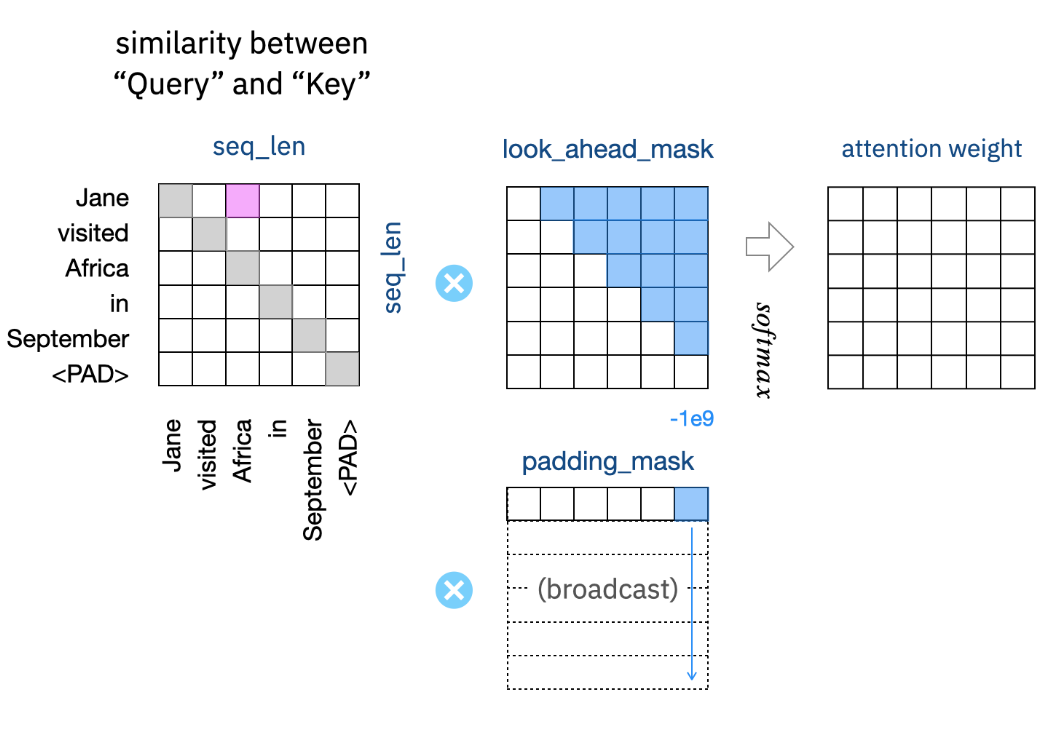
The first step in MHA for self-attention is to find similarity between Q (query) and K (key).
It is simply done by "dot product’. Remember that “dot product” is basically a “cosine similarity” from its definition.
a\cdot b = \parallel a\parallel \parallel b\parallel\cos\theta
If two vectors are similar, then, \cos\theta becomes close to 1. I suppose you remember “word embedding”. That’s I’m referring. This is one aspect of this MHA, but, think good for “intuitions” 
With this, we can create a similarity map, which is a base for attention weights. The key point is that we Q (and K, V also), includes both “word embedding and position encoding”. If it is only “word embedding”, then a cosine similarity is just for a word itself, not including any position information. That’s not what “attention” expects. With adding 'Position encoding", then, we can define a similarity from both “word vector” and “word position” view points
Then, we apply masks and create attention weights with Softmax (and some scale factors based on d_{model}, which is equal to “embedding_dim” in out case). Finally, we get the final output by a dot product of attention weights and V. Important thing is a mapping between k and v is also trainable.
Hope this helps some.