I am currently going through the Week 1 material of the 2nd course in the Machine Learning Specialization, and this is the first time I have come across W matrix defined with feature params (w1_1, w1_2, w1_3..) as column vector.
For example, in the CoffeeRoastingNumPy Optional Lab, W was defined as :
W = np.array( [[-8.93, 0.29, 12.9 ], [-0.1, -7.32, 10.81]] )
and, units = W.shape[1]
What’s the intuition for this ?
Instead, why not follow the same structure as in Course 1 ? Like :
W1 = np.array( [[-8.93, -0.1], [0.29, -7.32], [12.9, 10.81]] )
and, units = W.shape[0]
In this example, Training Set X is set as :
X = np.array([
[200,13.9],
[200,17]])
FYI : I tried out a row-vector implementation for W, and it gave same results. So I just want to understand if there is a good reason for using one approach vs the other.
Follow-up [Minor] :
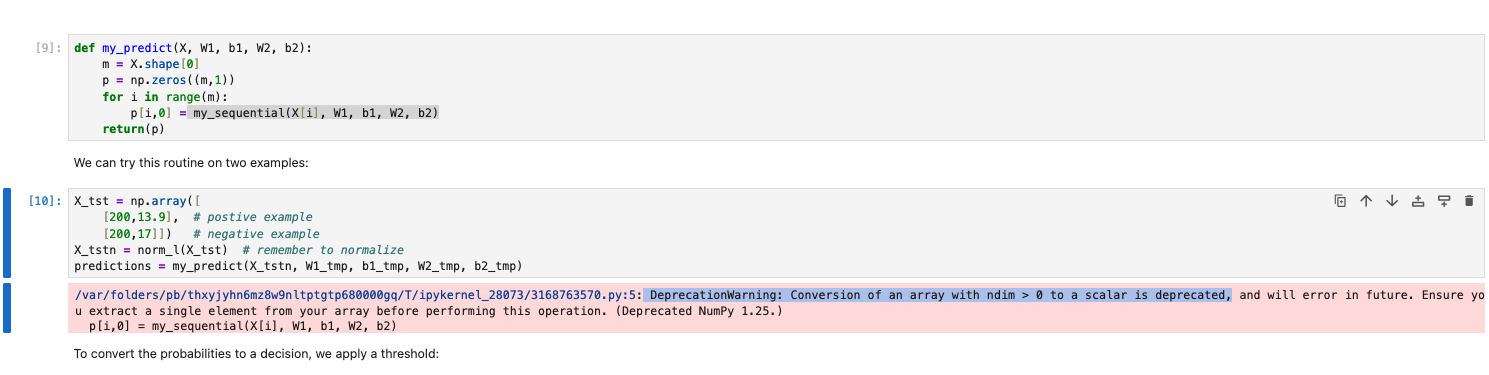
Need help with an error as I am new python numpy and tensorflow libraries.
When I run the same code module as the Optional Lab on my personal laptop, I get a " DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated," (screenshot attached). Anything I found online didn’t make a lot of sense to me, so I would appreciate some help here ?
Thanks a lot !! Cheers