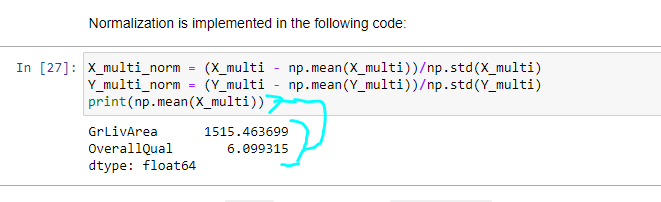
Why are we normalizing the values with respect to the mean of the whole dataset, as opposed to values in individual columns? For instance, GrLivArea and OverallQual have different units of measurement, so shouldn’t we normalize these rows ‘individually’? Or is np.mean/np.std already doing this for us?
Awesome! makes sense. Is this something specific to operations on Pandas Dataframes? According to numpy.mean — NumPy v1.26 Manual, if an axis is not specified it will attempt to take the mean of the flattened array.