In the Activation Function’s Video at 4:19 time Andew talks about how the slope of the Sigmoid Function can slow down the Gradient Descent stage.
However, the derivative that we are looking for, the dJ/dz, takes into account the Log of the Activation Funcion, instead of the A.F. itself. Please recap the Logistic Regression Cost Function J.
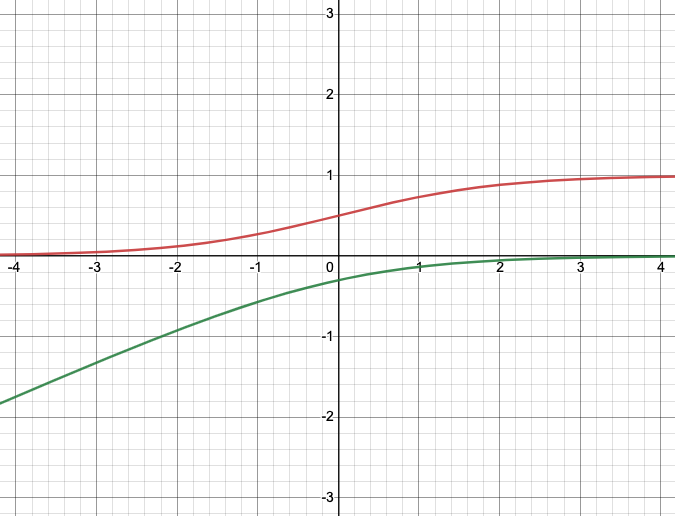
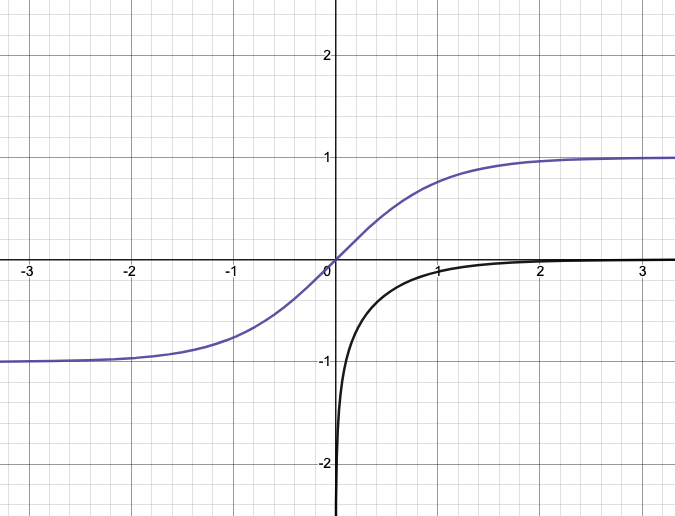
As we can see in the following plots, both functions (A.F. and its log) have different shapes, so different slopes.
For Linear regression, the derivative at the end node does consider the log of the activation function. But consider any activation function in any of the layers in between. I am sure you would agree it looks at the activation function. Actually in the linear regression also, it pays importance to log of the activation.
J = log(f(x)).
Then dJ/dx = 1/f(x)*d(f(x))/d(x) = 1/f(x) * derivative of the activation function.
Hope this clarifies!
I believe the reason for preferring the Tanh was just scaling of the inputs A to the next layers. Using Tanh they will be centered around zero which is supposedly an advantage.
The argument about the slope was for using the ReLU function in favor of the Sigmoid or Tanh.