I don’t understand why metadata filtering is done after rather than before
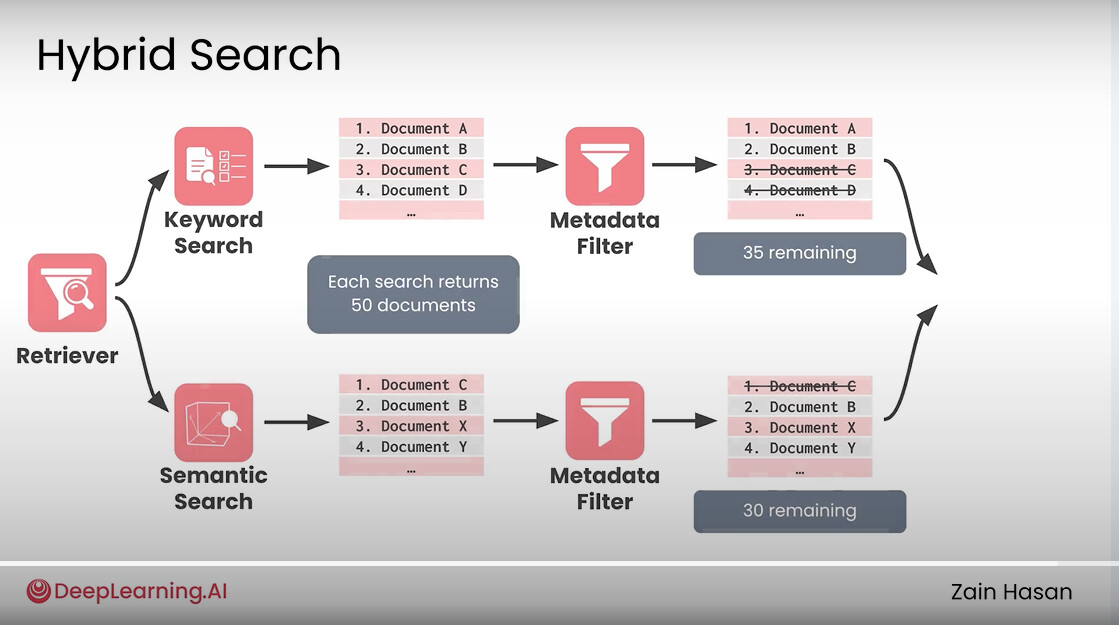
If we are going to discard documents, it makes more sense to discard them right away before wasting computational time to compute semantic similarity
I don’t understand why metadata filtering is done after rather than before
If we are going to discard documents, it makes more sense to discard them right away before wasting computational time to compute semantic similarity
Hi Billyboe.
The goal of retrieval is to maximize document coverage. The idea is to perform broad searches (keyword and semantic) to avoid missing potentially relevant documents.
Filtering (Metadata Filter) refines the search based on contextual criteria (date, type, author, permissions, etc.).
If we filter before retrieving, we limit the search universe and can exclude relevant documents that don’t meet metadata requirements but do meet content requirements.
It’s important to be concerned about computational cost because it affects various aspects of the RAG process, but at some point, you have to prioritize the process’s effectiveness in obtaining the best results, and this might mean slightly compromising on computational cost.
However, if you understand your data and the process, you could work in reverse; that is, filter first and then retrieve. This would depend on the use case and your knowledge of the data, but the primary reason shouldn’t be specifically computational cost.
Regards.
Ronweld
Goal of retrieval is to fetch relevant documents that match all metadata filters.
Retrieving all documents before applying metadata filtering is not only a waste of computational resources but could also lead to poor experience.
Let’s consider a shopping site like Amazon. Say I’m searching for “candy” under the “books” category. We know that a lot of items under the food category will be highly relevant. So, when fetching the 1st response, you’ll see fewer than a page full of book results when there are a lot more candidates under the books section.
So, pre-filtering based on metadata is the way to go to reduce the universe of documents prior to applying RAG due to the earlier mentioned reasons.
With this in mind, could you please provide an example of where it’s important to perform retrieval before filtering?
I don’t understand what you are saying.
You said “Retrieving all documents before applying metadata filtering is not only a waste of computational resources but could also lead to a poor experience”. I agree. You should apply metadata filtering before retrieval, not the other way around.
You provided an example where the user searched “candy” on Amazon under the “books” category. It makes much more sense to apply metadata filtering and remove the food items before retrieval, rather than applying retrieval on all items and removing the food items afterward. The food items are going to be removed one way or another, but it makes much more sense to remove them right away.
Then you asked me, “an example of where it’s important to perform retrieval before filtering”. Honestly none comes to mind.
My response was to @ribarola and the question wasn’t directed to you.
Adding @lucas.coutinho to this topic as well.
Hi all!
This is a valid point and a very intuitive argument. However, most vector DBs use ANN (aproximate nearest neighbour) methods like HNSW. That index is a graph built over the entire dataset. To “pre-filter,” the system would basically need to rebuild or reshape that graph on the fly so it only includes documents that match your filter. That’s hard or in some cases, practically impossible with the current algorithms.
On the other hand, ANN search is already very fast (log(N)), so even if your filter would reduce the dataset to, say, 1% of its size, the performance gain from pre-filtering isn’t as big as it sounds.
Because of that, most systems just run semantic search over the full index and then apply metadata filters afterward. There is ongoing research on better pre-filtering, but it’s not the most urgent problem right now given how fast ANN already is.
Regarding keyword search, the order does not matter because it uses a completely different data structure. Instead of a graph like HNSW, it uses an inverted index, which is basically a fast lookup table:
words → list of documents that contain that word
Because of that, keyword search can easily apply metadata filters before or during the lookup without needing to rebuild anything. It’s just set intersections, which are cheap.
I hope that answers your question!
Cheers,
Lucas
Thanks for the reply, Lucas.
Here’s a link that talks about how pre-filtering is done on metadata to provide more relevant context to underlying retrieval subsystem: