Hello,
A multiclass classification algorithm is an algorithm that you can use to predict for example one disease among 4. So, you need to use Softmax function.
I cannot understand this part of lab C2_W2_Softmax (a little) described in the next lines.
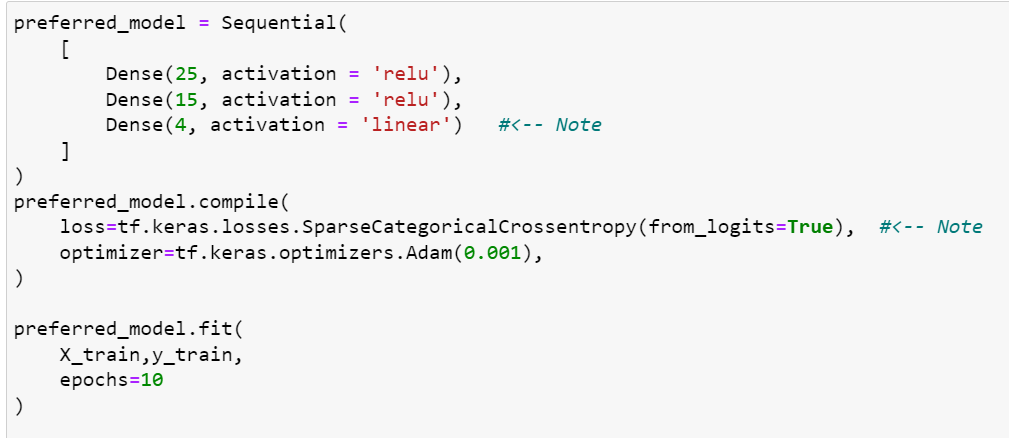
You are working in a multiclass classification algorithm, so the output is multiple categories. You apply these layers:
So far so good, but then it says you can apply a linear function for the last layer, and on the other hand, you don’t need to use Softmax to get the right category.
So if the algorithm is not required to get the result, Why should I study or use it? It sounds weird this part of the practice.
I understood that always you work with probabilities in classification. For that reason in a binary classification you predict with a threshold.
Thanks.
Regards.
Gus
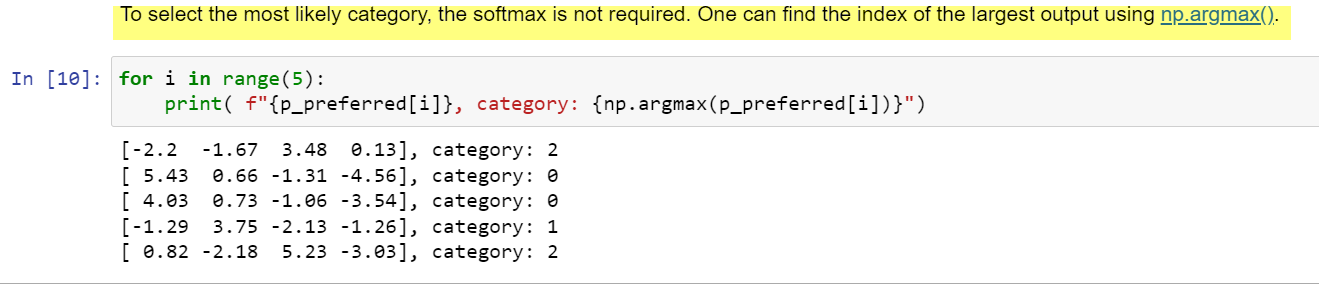
The trick is the from_logits = True argument to the BCE loss function. That means that the softmax is incorporated with the loss function for better stability. That is explained on this thread. But that does mean that you need to manually apply softmax when you make predictions with the final model after the training is complete. But note that softmax is monotonic, so the largest input will produce the largest output. So you can see which class is the prediction even without softmax.
So you actually are using softmax, but not by including it directly in the output layer of your defined network architecture.
Paul,
I didn’t know about the exact significance of the ‘from_logits = True’ command though we used it at times in DLS. But, now you’ve got me curious (I read the post you linked to, so I can gather the point and the significance)-- But how does it exactly manage to keep the results ‘numerically stable’ ?
I mean obviously our number of bits hasn’t changed.
It turns out that different ways to express the same computation can have different rounding and error propagation behavior. It matters exactly how you code things and sometimes being able to do both the activation and the loss together allows you to make improvements in the computation, meaning you get results in floating point that are closer to what you would get if we had the infinite resolution of \mathbb{R}.
If you want to go deeper and actually understand the kinds of things that make a difference, it requires that you investigate the field of math called Numerical Analysis. It’s not just hand-waving as I commented on that other thread. It’s real math, but that means it takes some work to study it.
I understood the numerically stable, there is a video about it, and as result you get a more precise number. That’s ok, so you apply Softmax and the end.
But the practice says you don’t need it to determine the category.
As a side note, Why a linear function at the end and not a relu function as the other ones? You should work with values from 0 to 1.
Thanks.
Gus
It is what I said earlier: both sigmoid and softmax are monotonic functions. Do you know what that means? The result is that the largest input produces the largest output. So softmax will make the results looks like a probability distribution, but you can predict which input will produce the largest probability by comparing the values of the inputs. The input value the farthest to the right on the number line will produce the highest probability.
Note that you can’t apply relu, because that distorts the results. All the inputs to softmax could be negative, right? Applying relu trashes all the negative values, so you lose the distinctions.
Understood, and thanks for the explanation @paulinpaloalto.
One more question, if you cannot apply relu at the end because you miss the negative values, Why relu is applied at the beginning?
Thanks.
Gus
The hidden layers are a completely separate consideration. ReLU is one of the possible activation functions to consider for the hidden layers. It doesn’t always work, but it is very cheap to compute, so it is always worth a try.
Just to be more complete in the explanation, there is no general requirement that we need negative inputs to a given internal or hidden layer of a neural network. The network will learn based on its inputs, although (as commented above) using ReLU as a hidden layer activation is not guaranteed to always work. It’s just that at the output layer if you are feeding the results to softmax as the output activation, then it would be a mistake to artificially alter the inputs to softmax by truncating the negative values in that specific case.
Ok thanks for the explanation @paulinpaloalto. Its not clear for me why the example uses ReLu if the Softmax should need negative value, and not uses linear. But on the other hands I watched a video that says all linear layers is not convinient (don’t remember why is that).
Thanks.
Regards.
Gus
It’s not that softmax particular needs negative values, but the point is that it can handle them. Here’s a simple example:
foo = np.array([[-1, -4, -10, -0.5]])
smfoo = softmax(foo)
print(f"smfoo = {smfoo}")
with np.printoptions(precision=4, suppress=True):
print(f"smfoo = {smfoo}")
smfoo = [[3.70558154e-01 1.84490042e-02 4.57305092e-05 6.10947111e-01]]
smfoo = [[0.3706 0.0184 0. 0.6109]]
There is no reason to artificially constrain the inputs to softmax: it can handle the full range (-\infty,\infty).
He he.
Just as an aside, follow-up, on rare occasion I will use ChatGPT to look up a concept I am not immediately familiar with-- not for ‘truths’, but just a rough outline for concepts/more in depth search.
In particular I wondered if ‘logit’ represented some technical term or more of a convention for programming.
The rough outline it gave back at least started to seem okay-- Until ChatGPT started to have some kind of seizure or something: