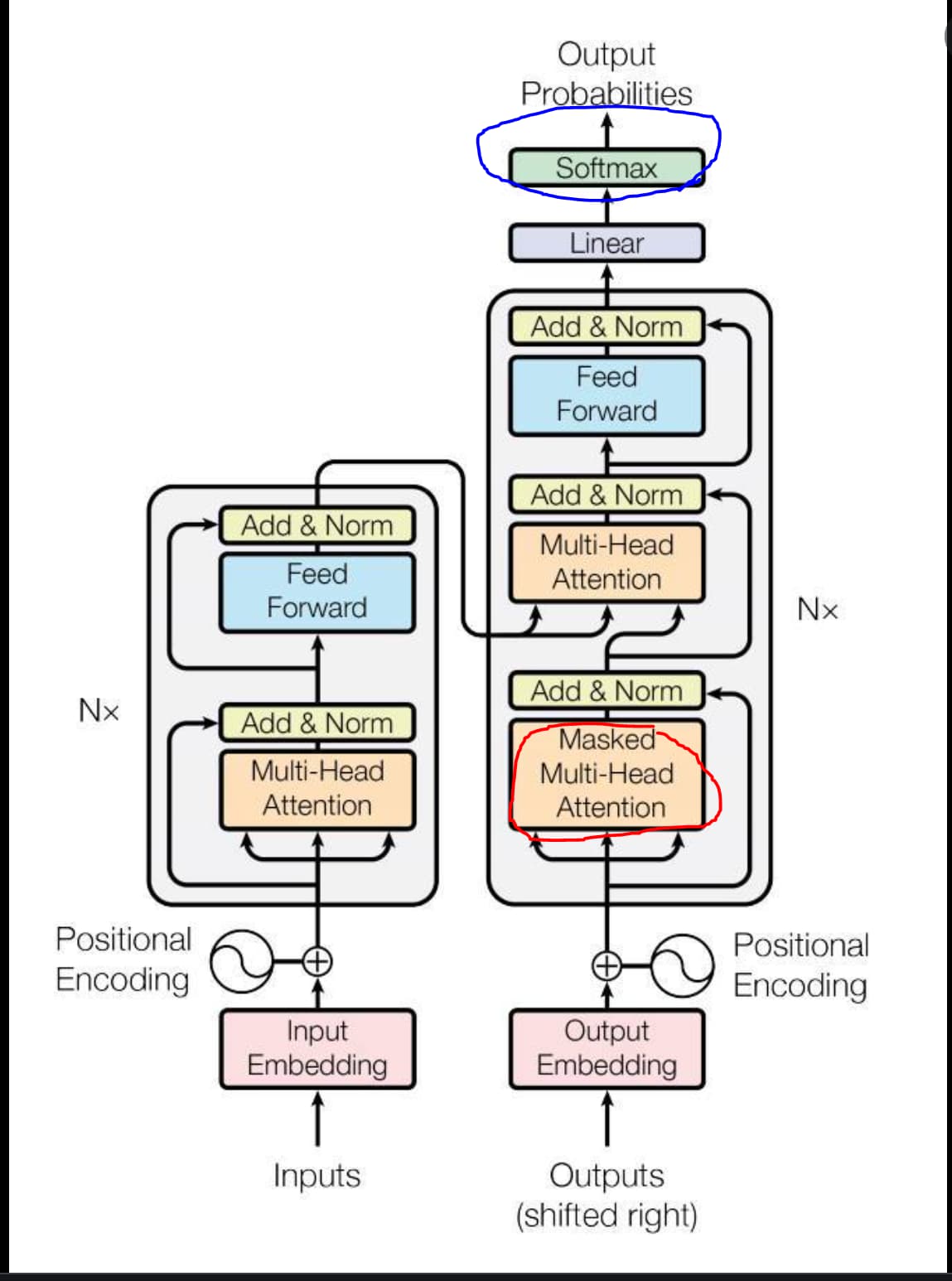
Softmax layer Clarification - Deep Learning Specialization / DLS Course 2 - DeepLearning.AI
In the above topic, we said that softmax is used in the output layer, not the hidden layer.
However, In the transformer, multihead attention is a hidden layer, and in multihead attention, QK^T passes through a softmax function… Why?
