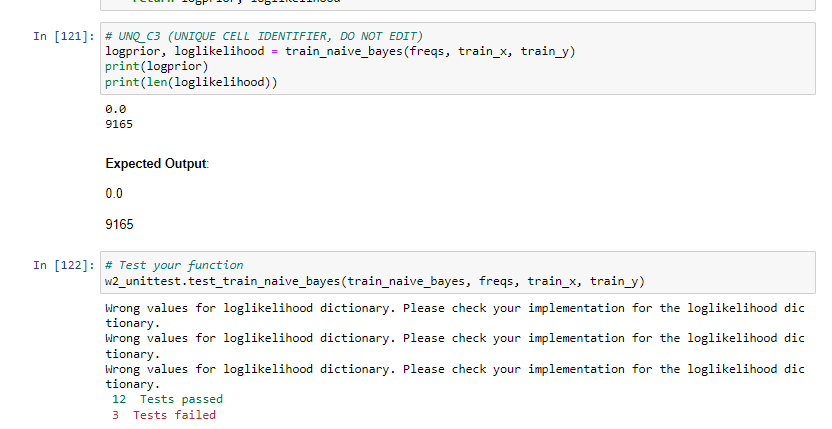
Wrong values for loglikelihood dictionary. Please check your implementation for the loglikelihood dictionary.
Wrong values for loglikelihood dictionary. Please check your implementation for the loglikelihood dictionary.
Wrong values for loglikelihood dictionary. Please check your implementation for the loglikelihood dictionary.
12 Tests passed
3 Tests failed
You’ve made what is probably the most common mistake on this function. When you count the positive and negative frequencies, you simply add 1 for each occurrence of a given word. What was intended was that you would add the actual frequency from the freqs dictionary for that.
Had the same problem as ad-1. Therefore I printed out the failed_cases list of the grader…and it found agreement in the numbers of all three tests (all are 9165 (see below). Despite of this, it still reported three failed tests:
Wrong values for loglikelihood dictionary. Please check your implementation for the loglikelihood dictionary.
Wrong values for loglikelihood dictionary. Please check your implementation for the loglikelihood dictionary.
Wrong values for loglikelihood dictionary. Please check your implementation for the loglikelihood dictionary.
12 Tests passed
3 Tests failed
[{‘name’: ‘default_check’, ‘expected’: 9165, ‘got’: 9165}, {‘name’: ‘smaller_check’, ‘expected’: 9165, ‘got’: 9165}, {‘name’: ‘smaller_unbalanced_check’, ‘expected’: 9165, ‘got’: 9165}]
Some tests have a pretty low bar for passage. Just because your output has the right shape is only step one. Just to make sure I’m understanding what you’re saying: did you find the solution based on the comments earlier on the thread? Or are you still working on it?
The code you show looks correct as far as I can see so far. Maybe I’m missing something. But I think maybe the error messages are not showing you the real values that it is unhappy about. Here’s another thing to try:
I added this code at the end of the last “for” loop to check my results for one particular word:
if word == 'smile':
print(f"freq_pos for smile = {freq_pos}")
print(f"freq_neg for smile = {freq_neg}")
print(f"loglikelihood for smile = {loglikelihood[word]}")
Here’s what I get when I run the test cells in the notebook with that in place (and a couple other print statements):
V: 9165, V_pos: 0, V_neg: 0, D: 8000, D_pos: 4000, D_neg: 4000, N_pos: 27547, N_neg: 27152
freq_pos for smile = 47
freq_neg for smile = 9
loglikelihood for smile = 1.5577981920239676
0.0
9165
V: 9165, V_pos: 0, V_neg: 0, D: 8000, D_pos: 4000, D_neg: 4000, N_pos: 27547, N_neg: 27152
freq_pos for smile = 47
freq_neg for smile = 9
loglikelihood for smile = 1.5577981920239676
V: 9165, V_pos: 0, V_neg: 0, D: 20, D_pos: 10, D_neg: 10, N_pos: 27547, N_neg: 27152
freq_pos for smile = 47
freq_neg for smile = 9
loglikelihood for smile = 1.5577981920239676
V: 9165, V_pos: 0, V_neg: 0, D: 15, D_pos: 10, D_neg: 5, N_pos: 27547, N_neg: 27152
freq_pos for smile = 47
freq_neg for smile = 9
loglikelihood for smile = 1.5577981920239676
All tests passed
What do you get if you try the little “instrumentation” like I did above for “smile”?
I assume you were just typing faster than you were thinking and you meant that N_pos is the sum for all positive occurrences and N_neg is the sum for all negative occurrences. Note that’s not what you actually said …
This is a great example of why variable and function names matter. It seems perfectly reasonable to assume that a count of positive examples would be stored in a variable named N_pos or Pos_count or some such. If what you really want to collect is a frequency, then do yourselves and your future maintenance programmers a solid and name the variable accordingly. Your future self and your future project manager thank you in advance.
I am also getting the wrong value for the length of loglikelihood . I get 11436 instead of 9165.
Also, when I add the test code:
if word == ‘smile’:
print(f"freq_pos for smile = {freq_pos}“)
print(f"freq_neg for smile = {freq_neg}”)
print(f"loglikelihood for smile = {loglikelihood[word]}")
After the last for loop, nothing gets printed. These print statements don’t get executed at all.
That is the number if you don’t construct the vocabulary correctly. You have taken every word from the keys of the freqs dictionary, but you need to reduce those to the unique values. Note that some (but not all) words have both positive and negative counts. Also note that they gave you a nice hint in the instructions for this section about how to get the unique values.
Thanks for the rapid response! I found the error. Working fine. Still don’t know why adding the test lines don’t print anything for me. talking about this snippet:
if word == ‘smile’:
print(f"freq_pos for smile = {freq_pos}“)
print(f"freq_neg for smile = {freq_neg}”)
print(f"loglikelihood for smile = {loglikelihood[word]}")
Maybe the contents of word is not what you expect. Is it the whole key value? That’s a tuple, right? Or maybe the word “smile” ends up not being in your vocab, although I doubt that is the case. You’d fail other tests in that case …