Hi @esssyjr.
The second option (pre-trained model) should be more than enough for your task mentioned above. It will work immediately.
BR
Honza
Hi @esssyjr.
The second option (pre-trained model) should be more than enough for your task mentioned above. It will work immediately.
BR
Honza
YOLO was a paradigm shift and disrupted the practice of applied computer vision when it was released circa 2015/2016. I think if you want to work in this field, it is profoundly important that you understand what was state of the art in 2015, and how and why YOLO changed the game. That said, Joseph Redmon no longer performs CV research due to his stand on the ethics of its use, and the original YOLO is no longer state of the art. So I don’t see it as an either/or dilemma. If you’re serious about working in the field, you can’t merely download the flavor of the day and get it to run without crashing a couple times - you need to understand why it was invented, what previous problem it solved, what remaining problems it hasn’t solved. Become a carpenter, not a person who sort of knows how to aim a nail gun.
Hello @essyjr,
What I meant by statement, one should have classified their data based on the features in the data/image(like resizing or segment) first and then split them into train/val split, rather than using the same validation data to train a newer model.
or the other approach would be split the 20 images into 10:10 train/val data then resize or image segment the 10 images in the train data and then do the model training based on your algorithm prerequisite.
in case a split of (12:4:4::training:val:test), then it is a better choice as you are not mixing the dataset and dividing them randomly. Further detecting object through specificity of your detection.
By doing this you would surely come across some pattern of understanding between your images random split, also giving insight into more detail features in object detection.
Regards
DP
Its sure sir, i belive with your statement. Thanks for the advice.
Thank you very much for the advice, i really appreciate it and i will look into it.
Do you have any resource you will suggest to me ?
Sure, I got you. Thanks for the advice.
@Deepti_Prasad
Hi @esssyjr.
I have written some basic code, so please try it. You DON’T need to train it from scratch, it simply works with original pre-trained model.
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
# image examples
img_dict = {
#'<key>' : '<url of the image>']
'car' : 'https://images.unsplash.com/photo-1605559424843-9e4c228bf1c2?q=80&w=1964&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D',
'cheetah' : 'https://upload.wikimedia.org/wikipedia/commons/0/08/Cheetah_%28Acinonyx_jubatus%29_%2816546676748%29.jpg',
'zebra' : 'https://i.imgur.com/KKuQH.jpeg',
'elephant' : 'https://i.imgur.com/Bvro0YD.png',
'phone' : 'https://upload.wikimedia.org/wikipedia/commons/c/ca/Siemens_AX72_mobile_phone.jpg',
'watch' : 'https://upload.wikimedia.org/wikipedia/commons/8/8b/DBA-800.jpg'
}
# Predict with the model
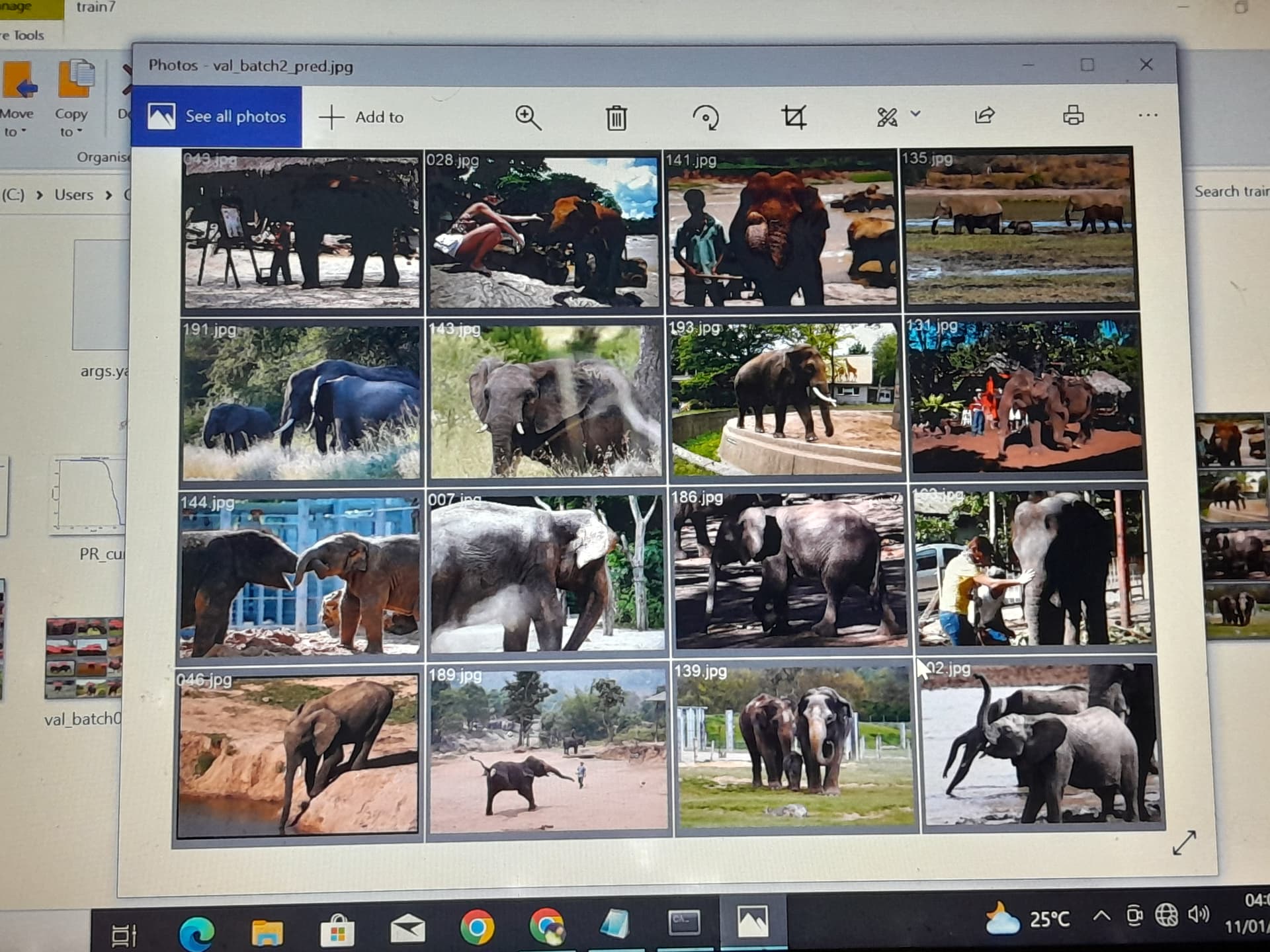
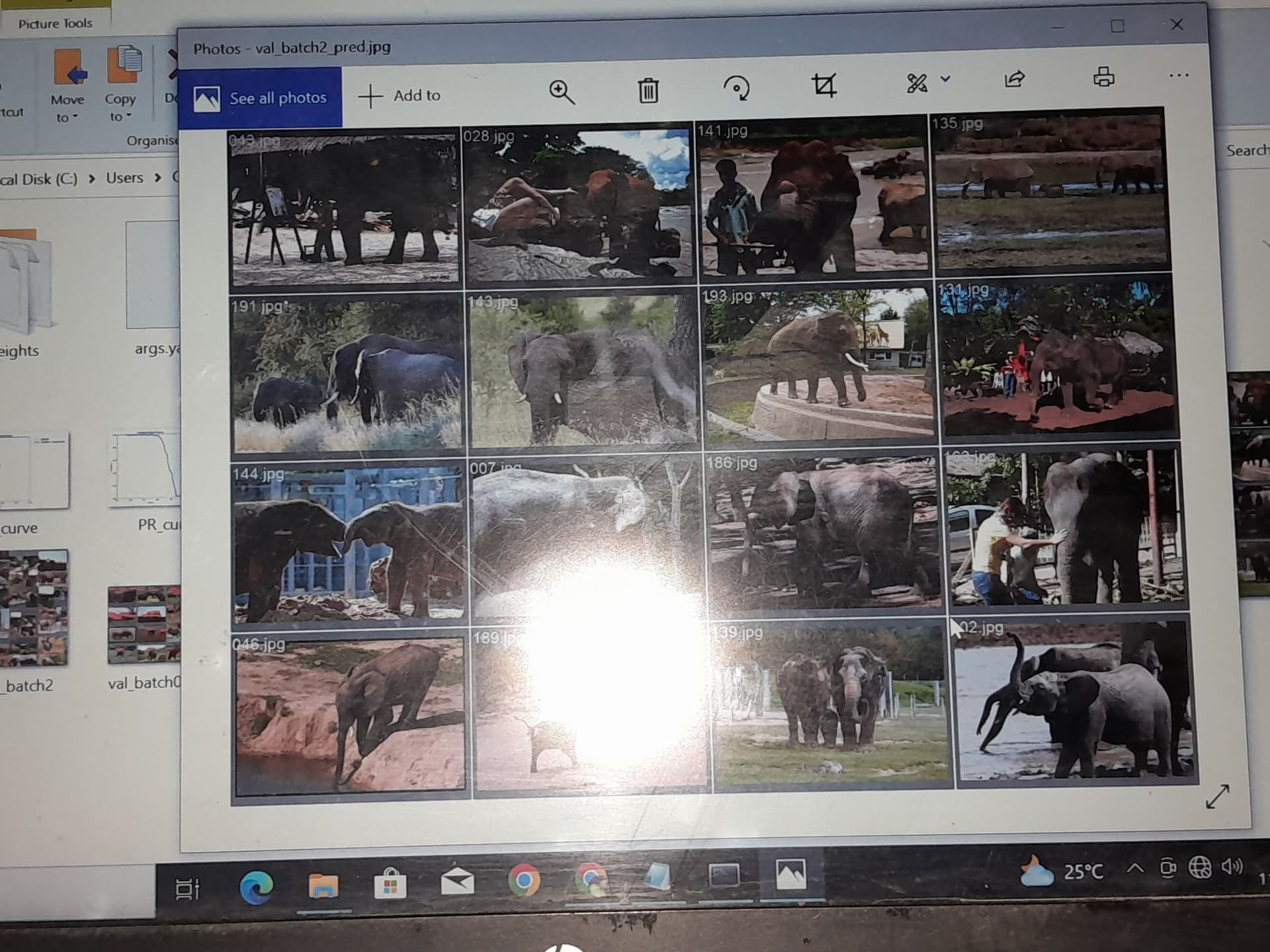
results = model(img_dict['elephant'], stream = False) # predict on an image
# Process results list (NOT used now, but it's the way how to use it further in code)
for result in results:
boxes = result.boxes # Boxes object for bbox outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
Hope it helps.
BR
Honza
PS: change the image as you wish by changing the key here:
results = model(img_dict['elephant'], stream = False)
This is just an example of a thought process for how to deepen one’s industry expertise…it isn’t a precise recipe.
For YOLO, read the academic paper(s). Look up the other models referenced or compared / contrasted. Understand how YOLO was similar or different. Look at the performance graphs. Where did YOLO outperform? What about the architecture would make you expect that outcome, or be surprised by it? Watch the videos of Mr Redmon demonstrating and explaining YOLO. Do you understand everything he says and how the model supports it? READ THE CODE. Look at the implementation used in this class, then look across github and find other people doing the same or almost the same thing with the Darknet baseline (which was not written in TensorFlow or Python). There are some 25,000 academic citations of the first YOLO paper since it was published in 2015/2016 - (Which by the way is favorably comparable to the citations of the original 1986 Nature paper on back propagation by Rumelhart, Hinton and Williams. Learning representations by back-propagating errors | Nature) - look some of them up. How was YOLO used and extended by other people? Where does the Ultralytics architecture fit in ? How is it similar to other YOLO architectures? Different? What limitations of the original YOLO architecture does it claim to address or mitigate?
If you just want to get a certificate for completing this Specialization, of course you don’t need to do any of this. If you really want to work in the field, prepare to do some homework. Jazz musicians call it woodshedding.
in this code even if you type
results = model(img_dict[‘elephant’], stream = False, show=True)
it will directly show the results
Correct @Ganesh_Gaitonde. I just wanted to show further post-processing to show original images with bounding boxes, etc. Main message was to show that objects like animals, etc. can be predicted just by the available pre-trained model without any additional effort.
BR
Honza
Hello @ai_curious,
My question is not related to the post thread.
I wanted to know the reason you emphasising on going through the detail YOLO from invention to its history in progress is to have better understanding of processing tools?
From your response I get that a thorough YOLO research would enable a person of better understand of analytical tool of object detection?
From the current point of view, what I got to know the most latest YOLO-NAS is the most robust algorithm with its reduction in latency and improvement of accuracy.
So basically the model upgradation are based on training data tried on older version or created YOLO object detection model?
The reason I asked the above question is the learner who raised the concerned wanted to train a data from scratch on YOLO algorithm which somehow didn’t let him find any detection with his training data. Does this means YOLO algorithm is not as versatile to take up any newer kind of training data?
Also I noticed while using static images, yolo8 seems to do better than long videos based on what I found on internet, So can a yolo algorithm with a stream=True could be created with object detection? would this still give better accuracy?
What are your views about what original yolo and latest version of Yolo lacks?
Thank you in advance.
Regards
DP
I think you should try to increase epoch value. I have trained yolov5 model with 1500 image dataset and my epoch value was like 200. If you increase epoch alot when you are using a small dataset it will cause overfitting but 2 epoch is very very low in my opinion. Also you can use roboflow to get labeled images for your dataset or find videos from youtube, download them and make your own dataset.
Tips for Best Training Results · ultralytics/yolov5 Wiki (github.com)
Hi @esssyjr. I’m not sure whether it’s still interesting for you, but here is an example w/ YOLO7 for path hole detection (transfer learning approach) with all the needed steps.
That’s definitely truth. I can confirm that after training several versions (5,7 & 8) of YOLO from scratch on my own labeled data. I had just around 30 labeled images (what’s normally too few - recommendation is ~1000+ per every class) and some positive results came first after 80-100 epochs.
Sorry I know I am late to helping but I ran into this same issue and found a solution. First, I used different annotations for my training and validation data. I used 18 images a for the training and 18 different images for validation. Granted, I had multiple objects per image and I was only trying to detect one class. Then I trained the yoloc8n.pt model on my data for 100 epochs and I was able to get object detection that I am very happy with.
as others have said, try to increase epoch value as 2 epochs is insufficient for it to learn, try to train with more data and for ~100 epochs and you should get some results, as the YOLOv8 model is relatively quick to converge